
 Présentation et démarche
Présentation et démarche
On présente ici deux analyses : celles des données du recensement de la population de 2012 puis de l’indice des prix mensuellement actualisé. Les variables sont directement récupérables sur le site de l’Insee. Pour le premier volet, on se restreindra à une approche commune en attendant une remise à plat du projet en fin d’année, qui s’orientera également vers une approche temporelle grâce aux données de 2017 publiées entre temps. De même pour le second volet, s’arrêtant à 2017 alors que les indicateurs sont publiés en continue jusqu’à aujourd’hui.
Un mot essentiel, la remise en question des données de l’Insee en France est assez coutumière, mais il est vrai qu’à Mayotte cela dépasse clairement l’entendement. L’Insee a pris le temps de publier sous format blog une discussion particulièrement intéressante de chaque argument sur lesquels elle est remise en question, malheureusement on entend encore des nombreux hauts placés les remettre en question. En fouillant un peu, en cherchant à être complémentaire au travail déjà produit et en imaginant que le débat soit fondé, on est alors heureux d’apprendre qu’à Mayotte, d’après ces hauts placés, il n’y a pas de sur-fécondité, pas de sur-mortalité, par de sur-recours aux pathologies infectieuses et encore plus fort, pas de sur-délinquance, etc. bref qu’à part un déficit de volume d’effectifs, déjà démontré avec les données de l’Insee, finalement tout va bien. Car « oui », dire que l’on est le double de ce que l’Insee avance, c’est diviser par deux fois plus chaque indicateur, l’exercice étant fait, voilà le constant que l’on en déduit. Cet effet est d’autant plus étonnant que les publications de l’Insee ne cesse de tirer la sonnette d’alarme sur la situation depuis plusieurs années, du point de vue de l’auteur de ce site, c’est une façon assez peu conventionnelle et extraordinaire de tirer sur l’un des défenseurs les plus pertinents et écoutés en France, mais bon comme l’a si bien dit son Directeur Général :
« On s’attaque au thermomètre plutôt qu’à la maladie »
Le raisonnement par l’absurde étant désormais fait, on partira du principe que les données de l’Insee sont fiables et que le projet proposé ici a un sens autant théorique que contextuel.
Ahhhhhh… Mayotte
Le territoire de Mayotte est une île mesurant 376 km2 et se situe géographiquement dans l’archipel des Comores, lui-même situé dans l’océan Indien. Elle se divise en deux îles principales nommées la Grande-Terre et la Petite-Terre (oui bah l’une est plus petite que l’autre).
Historiquement, Mayotte était un territoire autonome jusqu’en 1841, date à laquelle le sultan prend la décision de vendre l’île à la France du fait de la pression des territoires voisins. Mayotte devient ainsi française en 1848. L’île, qui n’a jamais appartenu aux Comores donc, maintient ce premier statut suite à un vote ultra-majoritaire en 1976. Toujours sur la demande de sa population, elle vote majoritairement pour devenir un département d’Outre-mer français en 2009 et accède au statut de zone ultrapériphérique de l’Union Européenne en 2014. Remettre en question l’appartenance de Mayotte à la France, peut revenir d’une certaine manière à remettre en question celle de ma bien-aimée Corse ou même, pourquoi pas, de l’Alsace et la Lorraine, après tous les Mahorais sont français depuis plus longtemps que certains territoires rattachés à l’Hexagone directement…
Le territoire de divise en 17 communes, se déclinant en 72 villages. La commune de Mamoudzou rassemblant la plus grande partie de la population de Mayotte, elle figure comme la capitale économique de l’île.
Synthétiquement sur le plan socio-démographique, on rappellera qu’il s’agit du département le plus jeune de France avec un habitant sur deux âgé de 17 ans ou moins. Environ la moitié des habitants est de nationalité étrangère, dont la moitié en situation irrégulière, représentant un volume de tout de même près de 100 000 personnes alimentant ainsi le folklore local que l’on connait. Le contexte global tourne autour de la précarité avec quatre logements sur dix en tôle, trois sur dix n’ont pas accès à l’eau courante et les trois quarts de la population vivant en deçà du seuil de bas revenus métropolitains. L’Illettrisme concerne un habitant sur trois, seulement une personne sur quatre de 15 ans ou plus sort du système scolaire avec un diplôme qualifiant. Enfin, le secteur tertiaire est le plus représenté sur le territoire (concerne huit habitants sur dix) et plus précisément un habitant sur deux travaille dans la fonction publique.
Toujours le plus synthétiquement possible et sur le plan sanitaire cette fois-ci, le territoire est sujet à de nombreuses épidémies chaque année, à minima une par an depuis quelques temps. A cela s’ajoute un fort déficit en professionnels de santé et donc défaut de prise en charge, expliquant (de par bien d’autres indicateurs) qu’une personne née à Mayotte a globalement dix années de vie en moins qu’en France Hexagonale. Les données sur l’environnement sont assez faiblardes et on serait curieux de voir ce qu’elles pourraient offrir au diagnostic en Santé de Mayotte. En terme de pathologie, le diabète est particulièrement présent, tout comme les maladies infectieuses. On s’arrêtera là, très sincèrement, sur le plan Santé, tout est plus haut qu’en il ne le faut pas et plus bas quand il ne le faut pas qu’ailleurs.
Enfin, sur le plan sécuritaire, qui touche terriblement ce bout de territoire qui, il y a encore une vingtaine d’années était l’un des derniers paradis de la surface du globe provoquant un véritable phénomène dépressif à l’idée de le quitter, depuis 2011 la situation ne cesse de s’empirer sur cet aspect. Vivre à Mayotte est tristement devenu pénible et l’on espère de tout cœur que les mouvements sociaux en cours permettront à l’île de partir sur une nouvelle dynamique positive car, réellement, ce département est magnifique doublée d’une richesse culturelle incroyable et mériterait d’être un développement à l’aune de toutes ses qualités.
On pourra retrouver les éléments plus complets ayant alimenté ce micro-diagnostic subjectif de Mayotte ici :
https://www.mayotte.ars.sante.fr/le-panorama-sante-de-lars-mayotte
, le document reprenant en plus tout le volet bibliographique présenté initialement ici et supprimé depuis. A compléter avec la page wikipedia :
https://fr.wikipedia.org/wiki/Mayotte
Exploitation des données du recensement de la population de 2012
Les données : https://www.insee.fr/fr/statistiques/2409395?sommaire=2409812
Les données utilisées sont celles du recensement de la population de 2012 à l’échelle de la commune et sont donc déclaratives. Une base de données de 118 variables peut être construite, que l’on ramène à 86 variables optimisées en fonction de la taille de l’effectif ventilé sur les variables d’origines. Étant donné que l’on se lance dans une étude typologique, avec pour objectif de montrer la ressemblance entre les différentes communes, on a considéré la part en pourcentage de la ventilation des différents champs au sein des différentes thématiques pour chaque commune prise individuellement (en somme, une ligne équivaut à une commune). En effet, considérer les effectifs bruts ou bien la part en pourcentage en fonction des totaux mène à des résultats biaisés par le fait qu’il est évident que plus une commune concentre d’individus et de ménages et plus ses effectifs seront grands.
Deux types de données sont regroupées, celles issues du bulletin individuel et celles issues de la feuille logement.
- Pour les premières on trouve :
– La répartition par classes d’âge en sept catégories (0-4 ans, 5-19 ans, 20-29 ans, 30-39 ans, 40-49 ans, 50-64 ans et 65 ans ou plus) ;
– La répartition par genre ;
– La répartition par nationalité (français, étranger) ;
– La répartition par lieu de naissance (né à Mayotte, né ailleurs en France, né à l’Étranger) ;
– La répartition selon le statut matrimonial (célibataire-veuf-divorcé, marié) chez les 15 ans ou plus ;
– La répartition en fonction d’être en couple ou non chez les 15 ans ou plus ;
– La répartition en fonction du logement antérieur à Mayotte ou non ;
– La répartition selon la Catégorie Socio-professionnelle (CSP), au sens du recensement et non du Bureau International du Travail (BIT), renseignée chez les 15 ans ou plus (a un travail, chômeur, étudiants, retraité-au foyer-autres inactifs) ;
– La répartition selon le niveau de diplôme chez les 18 ans ou plus (sans scolarité, sans diplôme, CEP-BEPC-CAP-BEP, BAC-BAC pro, diplôme du premier cycle, diplôme du second ou troisième cycle).
- Et enfin, pour les données issues de la feuille de logement :
– La répartition par catégorie de logement (résidence principale, résidence vacante, logement secondaire-occasionnel) ;
– La répartition par aspect du bâti (habitation de fortune, habitation en dur, habitation traditionnelle-en bois) ;
– La répartition par type de construction pour les résidences principales (individuel, collectif) ;
– La répartition par statut d’occupation pour les résidences principales (propriétaire du logement uniquement, propriétaire du logement et du sol, locataire, logé gratuitement) ;
– La répartition par nature du sol pour les résidences principales (en terre battue, en béton, carrelage) ;
– La répartition par nombre de pièces pour les résidences principales (1 pièce, 2 pièces, 3-4 pièces, 5 pièces ou plus) ;
– La taille des ménages pour les résidences principales ;
– La répartition selon l’accessibilité par véhicule pour les résidences principales ;
– La répartition selon le nombre de voitures pour les résidences principales (aucune, une voiture, deux ou plus voitures) ;
– La répartition selon la présence ou non du confort de base pour les résidences principales (un logement est classé comme ayant le confort de base s’il a les WC, la baignoire, l’électricité et l’eau à l’intérieur du logement, si un seul de ces 4 items manque alors le logement est classé sans confort) ;
– La répartition selon le type d’accès à l’eau pour les résidences principales (eau froide à l’intérieur du logement seulement, eau froide et chaude à l’intérieur du logement, absence d’eau à l’intérieur et accès via une BFM, absence d’eau à l’intérieur et accès via un autre moyen qu’une BFM) ;
– La répartition selon la présence ou non de WC pour les résidences principales,
– La répartition selon la présence ou non d’électricité pour les résidences principales ;
– La répartition selon la présence ou non de baignoire pour les résidences principales ;
– La répartition selon le type d’évacuation des eaux usées pour les résidences principales (par le sol, par les égouts, par une fosse septique ;
– La répartition selon la présence ou non de bacs à ordure pour les résidences principales ;
– La répartition selon le mode de cuisson des aliments pour les résidences principales (cuisson par feu de bois, cuisson par réchaud à pétrole, gazinières, autres modes de cuisson) ;
– La répartition selon la présence ou non d’ordinateur pour les résidences principales ;
– La répartition selon la présence ou non de téléviseur pour les résidences principales ;
– La répartition selon la présence ou non de réfrigérateur pour les résidences principales ;
– La répartition selon la présence ou non de congélateur pour les résidences principales ;
– La répartition selon la présence ou non de lave-linge pour les résidences principales.
Cet inventaire est à garder à l’esprit pour les analyses à venir, car c’est à travers ce sous-ensemble de variables que l’on établira les différentes typologies. Évidemment, la considération d’autres caractéristiques amènerait à des résultats sensiblement différents, toutefois il est bon de savoir que l’on a là toutes les données socio-démographiques de base permettant d’ériger un distinguo « communes dans une situation globalement précaire » versus « communes plus développées ».
L’Analyse :
L’étude se déroulera en deux étapes :
– La première étape consistera à procéder à une analyse exploratoire bivariée en faisant le point sur les corrélations entre les différentes variables au travers des coefficients de corrélation de Pearson, Spearman et Kendall puisque l’on a un jeu de données au format exclusivement continue et que de taille d’effectifs reste assez faible (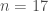 ) ;
) ;
– La seconde étape sera axée sur une étude typologique multivariée au travers d’une Analyse en Composantes Principales (ACP) et d’une Classification Ascendante Hiérarchique (CAH) afin de regrouper les communes en fonction des différents profils que l’on pourra mettre en évidence.
Donc on commence par la première phase des analyses. On lance sur l’ensemble des combinaisons, de 2 variables d’intérêt parmi les 86 variables présentes, le calcul des coefficients de corrélation cités ci-dessus, ce qui donne 3 655 combinaisons à éplucher. Le graphe ci-dessous présente le nombre de liaisons qui ressortent en fixant un 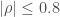 ,
,

En résumé sur l’ensemble des combinaisons et selon le seuil fixé, on a 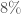 de corrélations significatives selon le coefficient de corrélation de Pearson,
de corrélations significatives selon le coefficient de corrélation de Pearson, 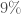 selon celui de Spearman et
selon celui de Spearman et  selon celui de Kendall. Face à autant de corrélations à parcourir, il convient de focaliser sur certaines variables importantes et partir du principe que l’on aura une vue plus exhaustive lors de l’approche multivariée. Ainsi, six thématiques sont jugées intéressantes, les croisements : avec l’âge, le genre, l’accès à l’eau, la CSP, la nationalité et le confort des logements.
selon celui de Kendall. Face à autant de corrélations à parcourir, il convient de focaliser sur certaines variables importantes et partir du principe que l’on aura une vue plus exhaustive lors de l’approche multivariée. Ainsi, six thématiques sont jugées intéressantes, les croisements : avec l’âge, le genre, l’accès à l’eau, la CSP, la nationalité et le confort des logements.
Pour les corrélations avec l’âge, quatre classes d’âges ressortent dans l’analyse bivariée. Les quatre figures qui suivent présentent les interactions avec la valeur du coefficient entre parenthèse et le sens de la corrélation (flèche) :
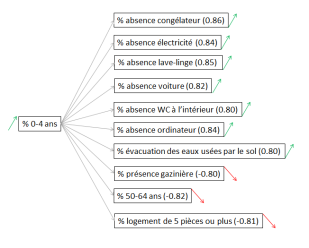
Globalement, la part des 0-4 ans croît avec celles du manque d’équipement et de la taille du logement. Assez logiquement, plus la part d’enfants en bas âge augmente et plus la part des personnes âgées diminue.
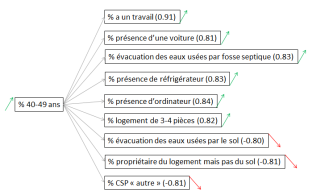
Globalement, la part des 40-49 ans croît en même temps que celles des conditions de vie et notamment le fait de travailler.

Globalement, la part des 50-64 ans croît en même temps que celles des équipements du ménage, des diplômés du BAC ou d’un BAC professionnel et du nombre de français.

Globalement, la part des 65 ans ou plus croît en même temps que celles des français et de ceux ayant l’eau froide seulement à l’intérieur du logement. A contrario, les parts des modes de cuisson par réchaud à pétrole et des étrangers diminuent quand elle augmente.
Pour les corrélations avec le genre, aucun croisement ne ressort, à la différence de l’accès à l’eau pour la part de ménages ayant seulement l’eau froide à l’intérieur du logement et pour celle des ménages s’approvisionnant en eau par un autre moyen que les BFM. Les deux figures qui suivent présentent les interactions avec la valeur du coefficient entre parenthèse et le sens de la corrélation (flèche) :

Globalement, la part des ménages avec seulement l’eau froide à l’intérieur du ménage croît en même temps que la qualité et la taille du logement.
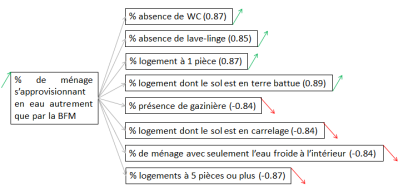
Globalement, la part des ménage s’approvisionnant en eau autrement que par la BFM croît en même temps que celles des logements précaires.
Pour les corrélations avec la CSP, deux catégories ressortent dans l’analyse bivariée, la part de ceux qui ont un travail et celle de ceux de CSP « autre » (retraité, au foyer, autres inactifs). Les trois figures qui suivent présentent les interactions avec la valeur du coefficient entre parenthèse et le sens de la corrélation (flèche) :

Globalement, la part de ceux qui ont un emploi croît avec celles des équipements du ménage ainsi que celle des 40-49 ans. De plus, elle est corrélée avec le niveau scolaire.

Globalement, la part de ceux ayant une CSP catégorisée « autre » croît avec l’absence d’équipements et de diplôme qualifiant. De plus, lorsque la part augmente, celles des 40-49 ans et 50-64 ans diminuent.
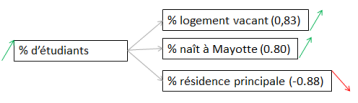
Globalement, la part d’étudiants croît en même temps que la part des catégories de logement et la part de nés à Mayotte.
Pour les corrélations avec la nationalité, les deux catégories ressortent dans l’analyse bivariée. Les deux figures qui suivent présentent les interactions avec la valeur du coefficient entre parenthèse et le sens de la corrélation (flèche) :
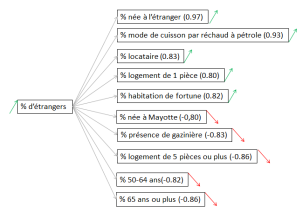
Globalement, la part des étrangers croît avec celles des logements précaires et de locataires. De plus, quand elle augmente, celles des 50-64 ans et des 65 ans ou plus diminuent.

Globalement, la part des français croît avec celles des logements de bonnes qualités. De plus, elle croît avec celles des 50-64 ans et des 65 ans ou plus.
Pour les corrélations avec le confort du logement, les deux catégories ressortent dans l’analyse bivariée. La figure qui suit présente les interactions avec la valeur du coefficient entre parenthèse et le sens de la corrélation (flèche) :

Globalement, l’indicateur du manque de confort reste assez robuste puisque, même s’il est basé sur uniquement quatre caractéristiques (WC à l’intérieur, baignoire, électricité, eau à l’intérieur), on voit que la part croît avec celles de l’absence de plusieurs autres équipements. De plus, quand elle augmente, celle des diplômés du BAC ou du BAC professionnel diminue. On notera que l’on ne présente pas l’analyse des corrélations avec la part des logements avec confort car elle conduit aux mêmes résultats inversés.
La seconde étape consiste donc à procéder à une analyse exploratoire multivariée au travers d’une ACP. Dans un premier temps, on détermine le nombre de composantes factorielles à retenir, on obtient alors le graphe de l’évolution des parts de variance suivant,

On constate que si on se limite aux deux premiers axes factoriels, c’est 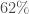 de la variance que l’on restitue. Pour une ACP cela semble un peu faible malgré le coude que l’on observe. Cependant, si on souhaite atteindre le gap classique de plus de
de la variance que l’on restitue. Pour une ACP cela semble un peu faible malgré le coude que l’on observe. Cependant, si on souhaite atteindre le gap classique de plus de 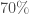 , on est obligé d’aller jusqu’à quatre axes factoriels, complexifiant un peu trop la lisibilité pour un gain plutôt limité. Afin de déterminer si on peut se limiter à deux composantes, on prend le temps de voir quelles oppositions chaque composante offre. On fixe le critère de significativité pour un coefficient sur la composante supérieur à
, on est obligé d’aller jusqu’à quatre axes factoriels, complexifiant un peu trop la lisibilité pour un gain plutôt limité. Afin de déterminer si on peut se limiter à deux composantes, on prend le temps de voir quelles oppositions chaque composante offre. On fixe le critère de significativité pour un coefficient sur la composante supérieur à 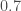 ou inférieur à
ou inférieur à 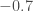 .
.
Pour la première composante, on constate l’opposition entre :
– La part des 40 à 64 ans, de ceux qui ont un emploi, de ceux ayant un BAC ou un BAC professionnel, de ceux ayant un diplôme du premier cycle, des logements en dur, des logements équipés d’un carrelage, des logements de trois pièces ou plus, des ménages avec une voiture, des logements catégorisés comme confortable, des logements équipés en WC, baignoire, électricité, ordinateur, téléviseur, réfrigérateur, congélateur, lave-linge et des logements dont l’évacuation des eaux usées se fait par fosse septique.
Soit des logements de bonnes qualités avec une population âgée qui travaille et est diplômée.
– Et la part des 0 à 4 ans, des CSP « autre » (retraité, au foyer, autres inactifs), des non scolarisés, des logements dont le sol est en terre, des logements de 1 à 2 pièce(s), des ménages sans voiture, des logements sans confort, des logements dont l’accès à l’eau se fait hors de la maison et pas par la BFM, des logements sans WC, sans électricité, sans baignoire, sans ordinateur, sans téléviseur, sans réfrigérateur, sans congélateur, sans lave-linge, dont l’évacuation des eaux usées se fait par le sol et dont le mode de cuisson se fait par le bois.
Soit des logements de mauvaise qualité, regroupant une grande part de jeunes enfants et d’une population en CSP « autre » et non scolarisée.
Pour la seconde composante, les oppositions sont déjà beaucoup moins nombreuses :
– La part des étrangers, de ceux nés à l’étranger, de ceux dont le logement antérieur n’était pas en France, de ceux ayant un diplôme du second ou troisième cycle, des locataires, de ceux ayant l’eau froide et chaude à l’intérieur du logement.
Soit une population étrangère diplômées et ayant un niveau de vie supérieur à la moyenne.
– Et la part des français, nés à Mayotte, dont le logement antérieur était à Mayotte, des étudiants et des logements vacants. Soit la population jeune et la population mahoraise.
Pour la troisième composante, on ne compte plus qu’une seule opposition significative : les logements collectifs versus les logement individuelles. Et pour la quatrième composante, aucune.
Ce premier bilan permet d’argumenter le choix de se restreindre à uniquement deux composantes étant donné que les composantes 3 et 4 n’apportent que peu d’information.
La figure ci-dessous présente la projection des variables sur les deux composantes retenues. En haut la projection de base et en bas le travail d’interprétation que l’on ajoute sur la figure de base :

Quatre groupes principaux et trois groupes de transitions se dégagent. L’ACP permet d’ériger une carte caractéristique du type d’habitat, ainsi on a en rouge des logements précaires, en bleu ceux des étrangers, en vert des logement plus confortable et en violet les logements moins précaires.
– En rouge (s’oppose directement au groupe vert) : la population des 0-4 ans, les non scolarisés, les logements de 2 pièces, les ménages sans voiture, les logements sans confort, sans électricité, sans baignoire, sans ordinateur, sans téléviseur, sans réfrigérateur, sans lave-linge, inaccessible pour les voitures, les logements dont l’évacuation des eaux usées se fait par le sol, les ménages ayant recours à un mode de cuisson par bois.
– Le premier groupe de transition en gris, situé au dessus du groupe rouge: les ménages ayant recours aux réchauds à pétrole, les logements de fortune, les logements d’une pièce, les ménages sans eau à l’intérieur du logement et n’allant pas à la BFM s’approvisionner, les logements sans congélateur et les logements dont le sol est en terre battue.
– En bleu (s’oppose directement au groupe violet) : les locataires, les résidences principales, les nés à l’étranger, les célibataires (ou veufs ou divorcés), les étrangers et les sans diplôme.
– Le second groupe de transition en gris, situé à droite du groupe bleu : les logements ayant l’eau froide et l’eau chaude à l’intérieur du logement, les diplômés du second et troisième cycle et ceux dont le logement antérieur n’était pas en France.
– En vert (s’oppose directement au groupe rouge) : les logements équipés de réfrigérateur, les 40-49 ans, les logements de 3-4 pièces, ceux qui travaillent, les logements équipés de téléviseur, d’ordinateur, de baignoire, d’électricité, de lave-linge, de WC, les diplômés du premier cycle, les logements avec confort, les ménages ayant une voiture, les logements dont le sol est en carrelage et les logements dont l’évacuation des eaux usées se fait par fosse septique.
– En violet (s’oppose directement avec le groupe bleu) : les diplômés d’un BAC ou d’un BAC professionnel, les logements avec congélateur, gazinière, les 50 ans ou plus, les logements de 5 pièces ou plus, les propriétaires du logement et du sol, les habitations en dur, les logements avec uniquement l’eau froide à l’intérieur et les français.
– Et le troisième groupe de transition en gris, et situé en bas du groupe violet : les nés à Mayotte, les résidences vacantes, ceux dont le logement antérieur était à Mayotte et les étudiants.
On a donc une première typologie avec le groupe rouge représentant la population des très précaires. Ensuite le groupe bleu, qui est indépendant au groupe rouge et au groupe vert, se situe à côté des deux groupes gris de transition (gauche, précarité, et haut, développé) et qui s’inscrit finalement dans une classe intermédiaire. Puis le groupe vert qui, en opposition directe avec le groupe rouge, indique une population plus riche et qui reste très proche du groupe violet qui présente une forte corrélation en fonction de la tranche d’âge et du nombre de français. Puis le dernier groupe de transition, désignant la population des mahorais, étudiants, dont l’opposition se fait directement avec le groupe bleu des étrangers. A noter que les trois groupes de transition en gris sont indépendants les uns des autres, soit précarité, développé et jeunesse non liés.
On va boucler l’étude en focalisant sur la ressemblance entre les communes au travers de la caractérisation obtenue par l’ACP. La figure suivante présente, à droite, la projection des observations soit des communes,

Afin d’objectiver le regroupement des communes, une classification ascendante hiérarchique est réalisée,

Quatre profils de communes se dégagent :
– Pamandzi, Dzadouzi et Sada, dont les projections coïncident avec la typologie des zones développées ;
– Boueni et Kani-Kéli, dont les projections coïncident avec l’autre typologie des zones développées;
– Chiconi, Mtsangamouiji, Acoua et Mtsamboro dont les projections coïncident avec la typologie des jeunes ;
– Mamoudzou, Chirongui, Dandrélé, Tsingoni, dont les projections coïncident avec la typologie des étrangers et des zones précaires ;
– Bandraboua, Koungou, Dembeni et Ouangani, dont la projection coïncident avec la typologie des zones précaires.
Et l’on finalise tout cela par un résultat visuel et simple à lire. On rappelle que l’on est sur les données de 2012 :

Analyse spatiale de l’indice des prix
Parmi les nombreux jeux de données récupérables depuis le site de l’Insee, il en est un particulièrement intéressant : l’indice des prix à la consommation. On dispose ainsi d’une série chronologique allant de 1999 à 2017. N’étant pas expert sur le sujet, il semble que les données sont réajustées en fonction d’une année de référence, nommée base, faisant qu’il est difficile de travailler directement sur l’ensemble de toute la série. Néanmoins, le site de l’Insee permet d’avoir une série actualisée débutant à janvier 2012 et disponible depuis cette page web (cf données complémentaires) :
– Série de données : https://www.insee.fr/fr/statistiques?debut=0&theme=80&categorie=2&geo=DEP-976
A toute fin utile, on rajoutera la page définissant les données utilisées ici : https://www.insee.fr/fr/metadonnees/definition/c1557
L’étude d’une telle série est l’occasion de se servir des outils d’analyse liés aux séries temporelles et aux chaînes de Markov. Mais avant cela, il est d’usage de décrire cette série de données au travers d’une analyse descriptive simple.

On a donc l’indice global des prix (bleu), celui lié à l’Alimentation (rouge), aux Services (orange), à l’Énergie (violet) et aux Produits Manufacturés (vert).
De manière général, l’indice des prix global a connu une forte hausse en 2012 qui se poursuit sur les cinq années suivantes mais de manière plus lente. Si l’on se réfère au graphe, les indices des prix de l’Alimentation et des Services augmentent depuis 2012, le premier nettement plus fortement que le second. A contrario, celui des Produits Manufacturés ne fait que chuter. Concernant celui des Énergies, il a connu une lente chute de 2012 à fin 2014 puis oscille jusqu’en mi-2017 pour finalement reprendre sa croissance en fin 2017. On s’attend à l’avenir à ce que l’indice des prix reprenne sa progression au vu des quatre autres courbes.
Si l’on raisonne en termes de taux de croissance mensuels, les éléments ci-dessous permettent une description plus précise du phénomène d’année en année :

A l’exception de l’année 2015 (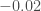 ), la croissance moyenne par mois est positive pour l’indice global des prix. Si elle reste relativement faible pour les années 2013 (
), la croissance moyenne par mois est positive pour l’indice global des prix. Si elle reste relativement faible pour les années 2013 (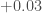 ), 2014 (
), 2014 (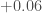 ), 2016 (
), 2016 (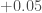 ) et 2017 (
) et 2017 (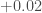 ), elle semble avoir connu un essor particulièrement important en 2012 (
), elle semble avoir connu un essor particulièrement important en 2012 ( ). Ce dernier constat est à relativiser étant donné la forte variabilité décrite par le calcul de l’écart-type,
). Ce dernier constat est à relativiser étant donné la forte variabilité décrite par le calcul de l’écart-type, 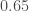 en 2012 versus
en 2012 versus 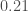 (2017),
(2017), 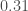 (2013, 2016),
(2013, 2016), 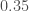 (2015).
(2015).
L’analyse des dotplots permet une caractérisation visuelle de la variabilité des taux de croissance mensuels pour chacune des sept années considérées :
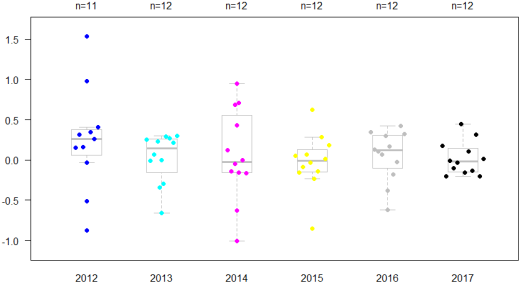
Cette approche met en évidence la grande variabilité évoquée des coefficients pour les années 2012 et 2014. Ce sont les années 2015 et 2017 qui, finalement, ont les plus faibles variabilités. Les années 2013 et 2016 montrant une tendance globale vers des taux de croissance mensuels négatifs à l’inverse de l’année 2017 dont la tendance est plutôt positive.
On peut également passer par une approche en trimestre en posant  la période de janvier, février, mars ;
la période de janvier, février, mars ; 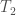 la période d’avril, mai, juin ;
la période d’avril, mai, juin ;  celle de juillet, août, septembre et
celle de juillet, août, septembre et 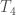 pour octobre, novembre, décembre :
pour octobre, novembre, décembre :

Il en ressort que les période avec les plus grandes variables sont le début de l’année () avec une tendance globale positive et le début du second semestre () nulle. étant particulièrement compact en termes de distribution tout comme .
- Approche par chaînes de Markov
On peut considérer une modélisation de l’indice des prix global par les chaînes de Markov. Via cette approche, il ne sera pas possible de dépasser l’ordre trois étant donné qu’au-delà le nombre de cas devient trop faible pour établir des trajectoires suffisamment robustes.
En codant 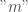 le cas où le coefficient de variation est inférieur à
le cas où le coefficient de variation est inférieur à 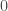 et
et 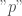 celui où il est supérieur à , on obtient les trois tableaux de trajectoires suivants avec en ligne les états précédents de la chaîne et en colonne l’état actuel :
celui où il est supérieur à , on obtient les trois tableaux de trajectoires suivants avec en ligne les états précédents de la chaîne et en colonne l’état actuel :

En prenant soin de considérer le rapport entre pourcentage de trajectoires et nombre de cas, on peut retenir les situations suivantes :
– pour l’ordre un, on a 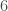 chances sur
chances sur 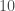 d’observer un coefficient positif après un coefficient négatif (trajectoire :
d’observer un coefficient positif après un coefficient négatif (trajectoire :  ).
).
– pour l’ordre deux,
 on a chances sur d’observer un coefficient positif après deux coefficients négatifs (trajectoire:
on a chances sur d’observer un coefficient positif après deux coefficients négatifs (trajectoire:  ) ;
) ;
on a chances sur d’observer un coefficient positif après un coefficient négatif suivi d’un coefficient positif (trajectoire : 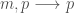 ) ;
) ;
on a chances sur d’observer un coefficient positif après un coefficient positif suivi d’un coefficient négatif (trajectoire : 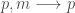 ).
).
– pour l’ordre trois,
on a  chances sur d’observer un coefficient positif après trois coefficients négatifs (trajectoire:
chances sur d’observer un coefficient positif après trois coefficients négatifs (trajectoire:  ) ;
) ;
on a chances sur d’observer un coefficient positif après deux coefficients négatifs suivis d’un coefficient positif (trajectoire: 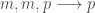 ) ;
) ;
on a 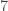 chances sur d’observer un coefficient positif après deux coefficients positifs suivis d’un coefficient négatif (trajectoire:
chances sur d’observer un coefficient positif après deux coefficients positifs suivis d’un coefficient négatif (trajectoire: 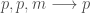 ) ;
) ;
on a chances sur d’observer un coefficient négatifs après trois coefficients positifs (trajectoire: 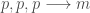 ).
).
Sur les huit cas que l’on a retenu, finalement deux sont inutiles ( et ) puisqu’ils présentent des probabilités similaires avec la trajectoire d’ordre un ).
En termes de prédiction, on est pour le mois de décembre 2017 sur un coefficient de variation positif mais on n’a pas pu déterminer de trajectoire suffisamment fiable pour rester sur l’ordre un. Si on se reporte à l’ordre deux, le mois de novembre 2017 est sur un coefficient de variation négatif ce qui renvoie au second cas de figure qui prédirait un coefficient positif en janvier 2018 dans cas sur . En jetant un œil à l’ordre trois, le mois d’octobre 2017 est également associé à un coefficient de variation négatif, ce qui prédit également un coefficient positif dans 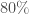 des cas. En consultant les données de l’Insee, on conste cependant que l’indice passe de
des cas. En consultant les données de l’Insee, on conste cependant que l’indice passe de  à
à 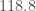 , soit une baisse, venant contredire cette prédiction.
, soit une baisse, venant contredire cette prédiction.
- Approche par série chronologique
L’échec de l’approche par chaîne de Markov est à modérer car les trajectoires retenues laissaient une grande part d’incertitude si l’on prend un peu de recul. On se propose cette fois-ci de passer par une tout autre approche, celle par série chronologique.
On a donc deux points à analyser avant de pouvoir se lancer dans les prédictions : la stationnarité et la saisonnalité. C’est deux points permettront de déterminer quel type de modèle l’on devra privilégier parmi les suivants : 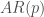 ,
, 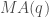 ,
, 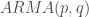 ,
,  ou
ou  .
.
L’étude des l’autocorrélogrammes est une étape importante dans l’analyse d’une série chronologique. Ci-dessous ceux obtenus sur les données :

On retrouve en haut à gauche la série de données d’origine et à sa droite l’autocorrélogramme. Ce dernier permet de tirer les cinq conclusions suivantes :
– Une décroissance lente des autocorrélations qui implique l’absence de stationnarité ;
– L’absence d’effet « sinusoïdale » des autocorrélations impliquant qu’il n’y a pas de saisonnalité ;
– L’aspect inversé qui dénote une inversion de tendance autour de la 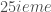 observation (soit janvier 2014) et qui peut s’expliquer par une saisonnalité observable de 2012 à 2013, tous les six mois, mais qui disparait pour les années 2014 à 2017 ;
observation (soit janvier 2014) et qui peut s’expliquer par une saisonnalité observable de 2012 à 2013, tous les six mois, mais qui disparait pour les années 2014 à 2017 ;
– Des autocorrélations qui, passées un retard de , deviennent non significatives ;
– Les autocorrélogrammes partiels (figure en bas à gauche) et inversés (en bas à droite) aurait tendance à s’orienter vers les paramètres 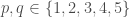 étant donné que pour ces lags, pas ou retard les autocorrélations restent significatives.
étant donné que pour ces lags, pas ou retard les autocorrélations restent significatives.
Cette première analyse permet d’exclure l’usage du modèle SARIMA qui est applicable aux séries présentant une saisonnalité et le modèle ARMA, quant à lui applicable à celles stationnaires . On s’orientera donc vers un modèle ARIMA.
Pour le choix du modèle optimal et donc des paramètres 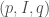 on va se baser sur les tests statistiques de Dickey-Fuller augmenté. Il faudra générer un nombre de lags, pas ou retards et fouiller dans les résultats des tests celui qui rejette l’hypothèse
on va se baser sur les tests statistiques de Dickey-Fuller augmenté. Il faudra générer un nombre de lags, pas ou retards et fouiller dans les résultats des tests celui qui rejette l’hypothèse 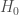 de racine unitaire.
de racine unitaire.
On va fixer un pas, lag ou retard de 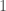 à
à 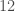 (en lien avec le nombre de mois sur une année) et observer le comportement des tests au fur et à mesure que l’on augmente le degré de différentiation
(en lien avec le nombre de mois sur une année) et observer le comportement des tests au fur et à mesure que l’on augmente le degré de différentiation 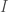 du modèle (et dont l’objectif est de rendre stationnaire le processus afin d’optimiser les prédictions). On obtient dés lors le tableaux de résultats suivants (le test « trend » pour l’étude de la tendance et le test single mean pour l’étude de l’écart à la moyenne globale):
du modèle (et dont l’objectif est de rendre stationnaire le processus afin d’optimiser les prédictions). On obtient dés lors le tableaux de résultats suivants (le test « trend » pour l’étude de la tendance et le test single mean pour l’étude de l’écart à la moyenne globale):

La condition pour retenir le meilleur modèle est le nombre de différentiation qui ne rejette pas pour les quatre tests ci-dessus. Plusieurs combinaisons ressortent, il convient alors de retenir la plus simple soit celle présentant le moins de lags, pas ou retards. C’est le cas qui nécessite 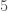 dérivations qui semblent répondre au mieux aux critères. Maintenant que l’on a déterminer le paramètre , il nous reste à déterminer ceux optimisant
dérivations qui semblent répondre au mieux aux critères. Maintenant que l’on a déterminer le paramètre , il nous reste à déterminer ceux optimisant  . Pour cela on teste les différentes combinaisons possibles dans l’ensemble que l’on a défini grâce à l’analyse des autocorrélogrammes et retenir celui qui minimise le critère
. Pour cela on teste les différentes combinaisons possibles dans l’ensemble que l’on a défini grâce à l’analyse des autocorrélogrammes et retenir celui qui minimise le critère 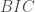 :
:

C’est donc le modèle ARIMA(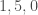 ) qui optimise la modélisation. Ce dernier étant établi, on passe maintenant aux prédictions. On génère alors le graphe suivant :
) qui optimise la modélisation. Ce dernier étant établi, on passe maintenant aux prédictions. On génère alors le graphe suivant :
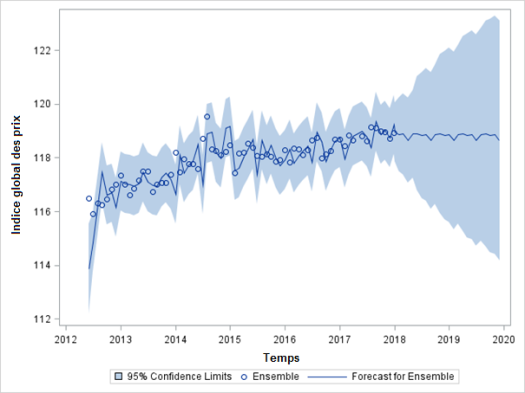
Pour l’année 2018, les prédictions envisagées de l’indice global des prix sont donc les suivantes :
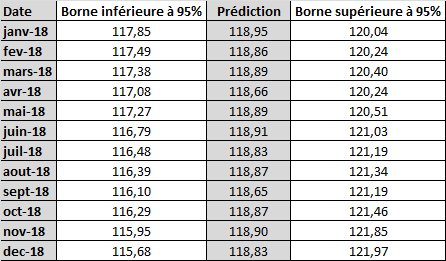
Si on compare avec les informations mises à disposition par l’Insee, il en ressort le constat suivant :
– Pour janvier, la valeur réelle de l’indice des prix global est de , le modèle ayant prédit une valeur très proche ( ) ;
) ;
– Pour février, la valeur réelle de l’indice des prix global est de  , le modèle ayant prédit une valeur peu éloignée (
, le modèle ayant prédit une valeur peu éloignée (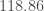 ) ;
) ;
– Pour mars, l’Insee n’a pas publié la valeur, aucun comparatif n’est possible ;
– Pour avril, la valeur réelle de l’indice des prix global est de 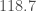 , le modèle ayant prédit une valeur très proche (
, le modèle ayant prédit une valeur très proche ( ) ;
) ;
En termes de tendance, le modèle avait prévu la chute de l’indice entre janvier et février (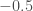 pour les valeurs réelles versus
pour les valeurs réelles versus 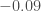 pour les valeurs prédites) mais avait également prédit une nouvelle chute pour avril alors que dans les faits l’indice global des prix est remonté (
pour les valeurs prédites) mais avait également prédit une nouvelle chute pour avril alors que dans les faits l’indice global des prix est remonté (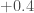 pour les valeurs réelles versus
pour les valeurs réelles versus  pour les valeurs prédites).
pour les valeurs prédites).
- Approche par régression linéaire multiple
Afin de conclure l’analyse, on proposons d’étudier la relation entre l’indice des prix global et ceux associés à l’Alimentation, aux Produits Manufacturés, à l’Énergie et aux Services. L’idée étant d’observer l’influence de chacun de ces indices sur le global.
Étant donné la nature des données qui sont de format continue, le modèle linéaire semble le plus approprié. Reste à définir si on reste sur une régression linéaire multiple ou si on opte pour sa version PLS. Afin d’argumenter ce futur choix, on regarde les matrices des corrélations de Pearson, Spearman et Kendall :

Les conclusions que l’on en tire à la lecture sont :
– Une forte corrélation linéaire entre les indices des prix de l’Alimentation et des Services avec l’indice global (respectivement 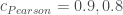 ). Ainsi, qu’une forte corrélation monotone décroissante avec les Produits Manufacturés (
). Ainsi, qu’une forte corrélation monotone décroissante avec les Produits Manufacturés (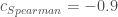 ). A contrario il n’y a pas de relation significative avec l’indice des prix associé à l’Énergie (
). A contrario il n’y a pas de relation significative avec l’indice des prix associé à l’Énergie (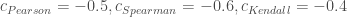 ).
).
– L’existence d’une forte multicolinéarité entre les indices des prix de l’Alimentation, des Produits Manufacturés, de l’Énergie et des services. Notamment la présence de deux groupes de variables avec, d’un côté, les indices associés à l’Alimentation et aux Services et, d’un autre côté, ceux de l’Énergie et des Produits Manufacturés.
Les corrélations et anti-corrélations sont particulièrement fortes, par conséquent on peut s’orienter vers un modèle linéaire PLS qui sera mieux adapté. La subtilité revient alors à déterminer le nombre de composantes PLS à retenir pour définir les coefficients de régression finaux. Pour cela, on étudie les performances du modèle en fonction de la variance expliquée pour les quatre composantes calculables :

On constate que la première composante explique 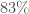 de la variance des quatre variables explicatives et
de la variance des quatre variables explicatives et 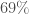 avec la variable à expliquer (Indice des prix global). En poussant le nombre de composantes, on parvient à des résultats très bons pour trois composantes,
avec la variable à expliquer (Indice des prix global). En poussant le nombre de composantes, on parvient à des résultats très bons pour trois composantes,  pour les deux. Par conséquent, le choix de trois composantes peut être retenu, ce qui donne les coefficients de régression linéaire PLS suivants :
pour les deux. Par conséquent, le choix de trois composantes peut être retenu, ce qui donne les coefficients de régression linéaire PLS suivants :

La sortie des coefficients permet de déterminer le poids des différents indices ainsi que leur influence sur l’indice des prix global. Ainsi, ce sont les indices liés à l’Alimentation et aux Produits Manufacturés qui pèsent le plus dans la croissance ou la décroissance de l’indice des prix global. Et si on se reporte aux coefficients standardisés, on en conclut que l’indice des prix de l’Alimentation a un impact fois plus important que celui de l’Énergie et 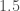 fois plus important que celui des Services. Quant à celui des Produits Manufacturés, le rapport de force est de fois plus important par rapport aux Énergies et
fois plus important que celui des Services. Quant à celui des Produits Manufacturés, le rapport de force est de fois plus important par rapport aux Énergies et  fois plus important pour les Services. C’est donc le rapport de force entre Alimentation et Produits Manufacturés qui sera déterminant, sachant qu’il tourne en faveur du premier avec un coefficient de
fois plus important pour les Services. C’est donc le rapport de force entre Alimentation et Produits Manufacturés qui sera déterminant, sachant qu’il tourne en faveur du premier avec un coefficient de  fois plus impactant que le second.
fois plus impactant que le second.



 au modèle
au modèle 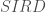
 et le modèle
et le modèle 
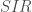 précurseur des modèles épidémiologiques complexes modernes. Enfin, deux dernières personnalités emblématiques :
précurseur des modèles épidémiologiques complexes modernes. Enfin, deux dernières personnalités emblématiques :  , et son maximum :
, et son maximum :  . De cette manière, on fixe déjà la temporalité
. De cette manière, on fixe déjà la temporalité 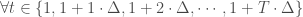 sur laquelle la modélisation sera réalisée. Enfin, on note
sur laquelle la modélisation sera réalisée. Enfin, on note  la somme des effectifs de tous les compartiments utilisés, soit la population total étudiée.
la somme des effectifs de tous les compartiments utilisés, soit la population total étudiée.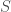 pour « Susceptibles », soit les susceptibles d’être contaminés car sains, et il ne faut pas confondre un individu sain avec un individu immunisé.
pour « Susceptibles », soit les susceptibles d’être contaminés car sains, et il ne faut pas confondre un individu sain avec un individu immunisé. ![\beta \in [0,1]](https://s0.wp.com/latex.php?latex=%5Cbeta+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=404040&s=0&c=20201002) ,
,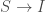 à chaque instant
à chaque instant 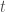 . Ces deux premiers compartiments forment à eux-seuls le modèle
. Ces deux premiers compartiments forment à eux-seuls le modèle 
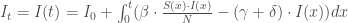
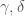 sont supposés nuls, on y reviendra plus tard.
sont supposés nuls, on y reviendra plus tard. 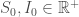 , et on érige le système
, et on érige le système 

 . Dès lors, on passe du phénomène assez rare d’infections virales chroniques sans réelle conséquence à n’importe quelles maladies dont on guérit mais ne meurt pas, spectre particulièrement large et dont on pourrait citer le rhume en guise d’exemple. L’ajout de ce compartiment se fait avec celui du paramètre
. Dès lors, on passe du phénomène assez rare d’infections virales chroniques sans réelle conséquence à n’importe quelles maladies dont on guérit mais ne meurt pas, spectre particulièrement large et dont on pourrait citer le rhume en guise d’exemple. L’ajout de ce compartiment se fait avec celui du paramètre ![\gamma \in [0,1]](https://s0.wp.com/latex.php?latex=%5Cgamma+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=404040&s=0&c=20201002) traduisant mathématiquement le taux de guérison. Le volume/effectif associé au compartiment
traduisant mathématiquement le taux de guérison. Le volume/effectif associé au compartiment 
 , et on érige le système
, et on érige le système 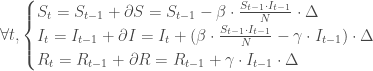
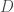 . Il s’agit des personnes infectées par la maladie et qui en sont décédées. Ces modèles
. Il s’agit des personnes infectées par la maladie et qui en sont décédées. Ces modèles 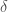 retranscrivant le taux de mortalité. Le volume/effectif associé à ce compartiment et à l’instant
retranscrivant le taux de mortalité. Le volume/effectif associé à ce compartiment et à l’instant 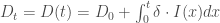
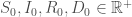 , et on érige le système
, et on érige le système 
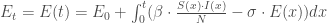

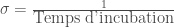
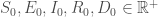 , et on érige le système
, et on érige le système 

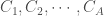 les différentes classes ou intervalles d’âge paramétrés et
les différentes classes ou intervalles d’âge paramétrés et ![\forall a_1, a_2 \in \lbrace 1, \cdots, C_A \rbrace, c_{a_1, a_2} \in [0,1]](https://s0.wp.com/latex.php?latex=%5Cforall+a_1%2C+a_2+%5Cin+%5Clbrace+1%2C+%5Ccdots%2C+C_A+%5Crbrace%2C+c_%7Ba_1%2C+a_2%7D+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=404040&s=0&c=20201002) le taux de contact entre les classes d’âge
le taux de contact entre les classes d’âge 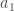 et
et 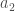 . Le modèle épidémiologique s’en voit fortement enrichi puisqu’il intègre dans son concept les probabilités de transiter d’une classe d’âge à l’autre. Si l’on prend par exemple le modèle
. Le modèle épidémiologique s’en voit fortement enrichi puisqu’il intègre dans son concept les probabilités de transiter d’une classe d’âge à l’autre. Si l’on prend par exemple le modèle 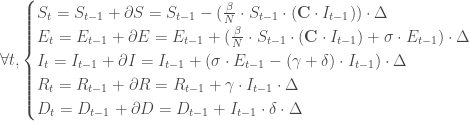
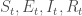 et
et  des vecteurs de taille
des vecteurs de taille  des volumes ventilés par classe d’âge.
des volumes ventilés par classe d’âge. ;
;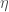 ;
; .
.
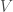 , intégrant à la fois le taux de vaccinés de départ et celui de nouveaux vaccinés ;
, intégrant à la fois le taux de vaccinés de départ et celui de nouveaux vaccinés ; , intégrant le taux de mis en quarantaine, de guéris et de décès en quarantaine ;
, intégrant le taux de mis en quarantaine, de guéris et de décès en quarantaine ;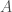 , intégrant le taux d’infectieux asymptomatiques qui présentent un enjeu important lors du contrôle d’une épidémie du fait qu’ils sont capables d’infecter d’autres porteurs sains et quasi-impossible à repérer ;
, intégrant le taux d’infectieux asymptomatiques qui présentent un enjeu important lors du contrôle d’une épidémie du fait qu’ils sont capables d’infecter d’autres porteurs sains et quasi-impossible à repérer ;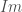 , et son taux associé ;
, et son taux associé ; 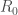 ou « Nombre de Reproduction de Base » est une mesure cruciale en épidémiologie, offrant des indications sur la transmission d’une maladie dans une population (à ne pas confondre avec le volume/effectif d’individus du compartiment
ou « Nombre de Reproduction de Base » est une mesure cruciale en épidémiologie, offrant des indications sur la transmission d’une maladie dans une population (à ne pas confondre avec le volume/effectif d’individus du compartiment  ). Il s’agit du
). Il s’agit du ;
; ,
,  ;
; ,
,  ;
; ,
, 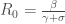 ;
;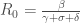 .
. (nombre de reproduction effectif instantané). Sa formule, quel que soit la forme du modèle est :
(nombre de reproduction effectif instantané). Sa formule, quel que soit la forme du modèle est : 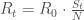
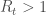 correspond à une épidémie en pleine propagation puisqu’un individu infecté en contamine au moins un,
correspond à une épidémie en pleine propagation puisqu’un individu infecté en contamine au moins un, 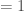 lorsqu’elle stagne avec un infecté qui contamine un seul sain, et
lorsqu’elle stagne avec un infecté qui contamine un seul sain, et 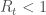 pour son déclin, un infecté en contamine moins d’un.
pour son déclin, un infecté en contamine moins d’un. 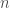 est de la forme générale :
est de la forme générale : 
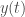 fonction adaptée à la forme des compartiments que l’on veut considérer dans le modèle et de forme :
fonction adaptée à la forme des compartiments que l’on veut considérer dans le modèle et de forme : 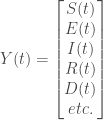
 une équation différentielle ordinaire du premier ordre avec la condition initiale
une équation différentielle ordinaire du premier ordre avec la condition initiale 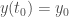 , où
, où 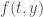 est continue dans une région rectangulaire
est continue dans une région rectangulaire  et
et 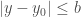 . Si
. Si 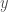 dans
dans 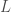 telle que
telle que  pour tous
pour tous  et
et 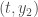 dans
dans  , où
, où  est le plus petit des nombres
est le plus petit des nombres  et
et  .
.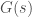 avec
avec  variable de Laplace.
variable de Laplace.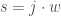 ,
,  unité imaginaire et
unité imaginaire et  fréquence angulaire.
fréquence angulaire. , on peut conclure en la stabilité du système si et seulement si la courbe ne contourne pas le point critique
, on peut conclure en la stabilité du système si et seulement si la courbe ne contourne pas le point critique 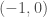 .
.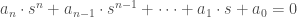 .
.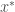 d’un système dynamique décrit par l’équation différentielle :
d’un système dynamique décrit par l’équation différentielle : 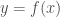 , où
, où  est un vecteur d’état dans
est un vecteur d’état dans  est une fonction continue, et
est une fonction continue, et  .
. 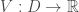 définie positive, c’est-à-dire que
définie positive, c’est-à-dire que 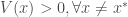 , avec
, avec 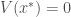 . De plus, considérons une fonction définie sur
. De plus, considérons une fonction définie sur  .
. 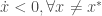 , alors l’équilibre est asymptotiquement stable au sens de Lyapunov. En d’autres termes, la fonction
, alors l’équilibre est asymptotiquement stable au sens de Lyapunov. En d’autres termes, la fonction 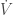 joue le rôle d’une mesure de la stabilité du système. Si
joue le rôle d’une mesure de la stabilité du système. Si 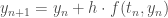 ;
;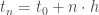 ,
,  une estimation de
une estimation de 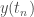 , et
, et 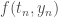 est la dérivée de
est la dérivée de 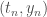 .
.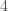 (
( ) sont aujourd’hui les plus largement utilisées pour résoudre une variété de problèmes scientifiques, y compris les modèles mathématiques en épidémiologie, en offrant
) sont aujourd’hui les plus largement utilisées pour résoudre une variété de problèmes scientifiques, y compris les modèles mathématiques en épidémiologie, en offrant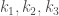 , et
, et 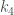 comme suit,
comme suit,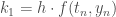 ;
; ;
; ;
;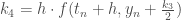 .
.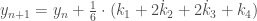 ;
;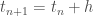 ;
; sur un territoire
sur un territoire 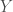 selon un modèle
selon un modèle 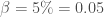 , avec une durée d’incubation de
, avec une durée d’incubation de  , le taux de guérison
, le taux de guérison 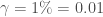 et le taux de décès associé à
et le taux de décès associé à 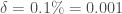 . On veut que ce modèle donne des prévisions sur
. On veut que ce modèle donne des prévisions sur  « temps » avec un pas
« temps » avec un pas  .
.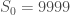 individus sains,
individus sains, 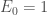 infecté introduit dans la population concernée et dont les symptômes ne sont pas encore apparus (« exposé »),
infecté introduit dans la population concernée et dont les symptômes ne sont pas encore apparus (« exposé »), 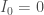 infecté avec symptômes,
infecté avec symptômes, 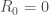 guéri et
guéri et 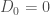 décédé par la pathologie
décédé par la pathologie 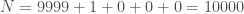 .
. 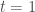 ,
,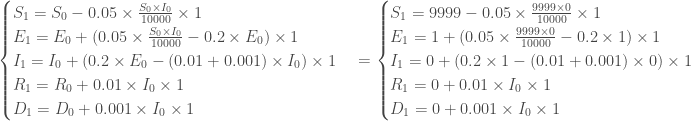
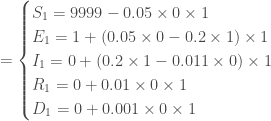
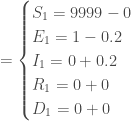
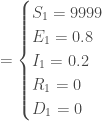
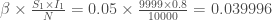
 ,
,
 ,
,

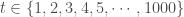 . Et si l’on affiche le graphe que l’on obtient avec les différents vecteurs associés à chacun des compartiments
. Et si l’on affiche le graphe que l’on obtient avec les différents vecteurs associés à chacun des compartiments  alors on obtient la figure suivante :
alors on obtient la figure suivante :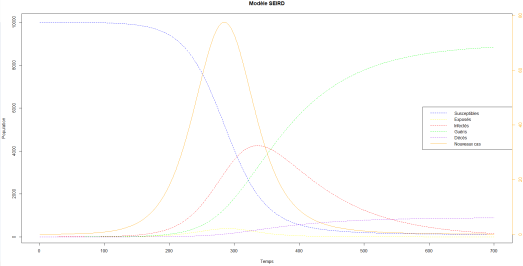
 individus ont été infectés, soit
individus ont été infectés, soit  de la population totale ;
de la population totale ;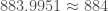 individus en sont décédés, soit
individus en sont décédés, soit  de la population totale ;
de la population totale ;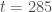 avec
avec 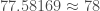 nouveaux cas à ce temps-là.
nouveaux cas à ce temps-là.
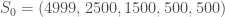 individus sains pour les différentes classes d’âge,
individus sains pour les différentes classes d’âge, 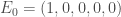 infecté, de 0-20 ans, introduit dans la population concernée et dont les symptômes ne sont pas encore apparus (« exposé »),
infecté, de 0-20 ans, introduit dans la population concernée et dont les symptômes ne sont pas encore apparus (« exposé »), 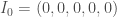 infecté avec symptômes,
infecté avec symptômes, 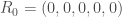 guéri et
guéri et  décédé par la pathologie
décédé par la pathologie 

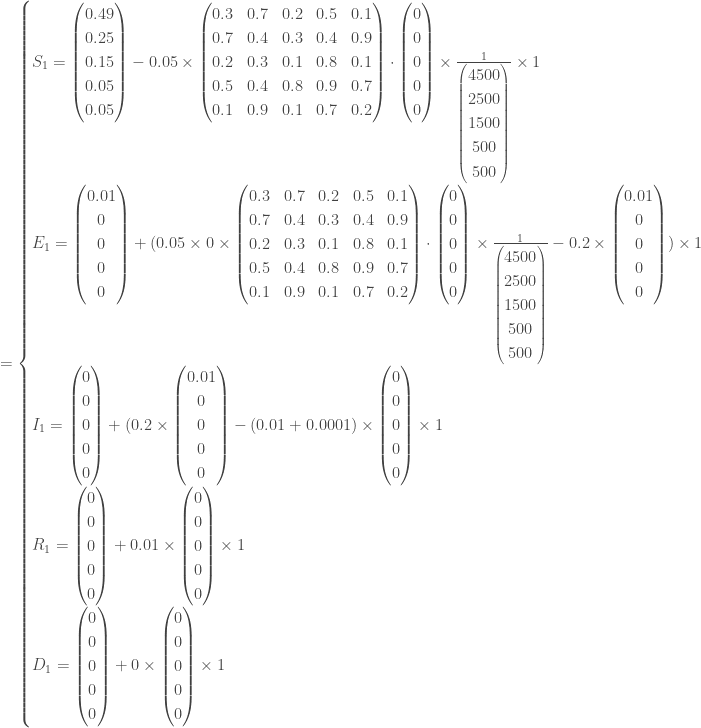
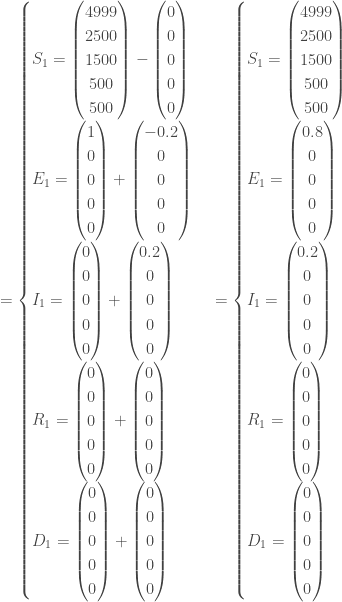

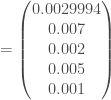

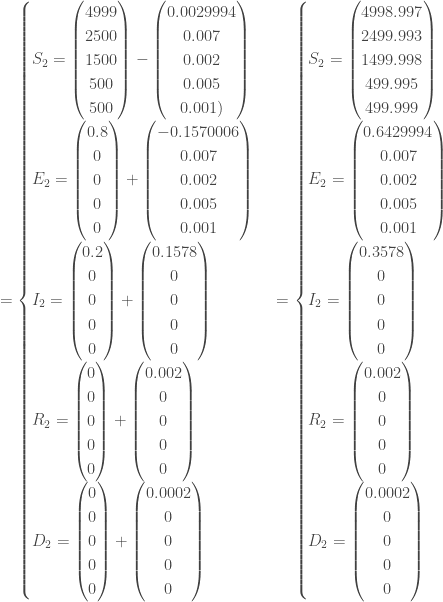




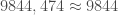 individus ont été infectés, soit
individus ont été infectés, soit  de la population totale ;
de la population totale ;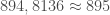 individus en sont décédés, soit
individus en sont décédés, soit  de la population totale ;
de la population totale ;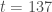 avec
avec 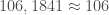 nouveaux cas à ce temps-là.
nouveaux cas à ce temps-là.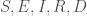
 ;
;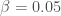 ;
; ;
; ;
; .
.


 de n’importe quel format (continue, binaire, etc.) à partir d’une matrice de
de n’importe quel format (continue, binaire, etc.) à partir d’une matrice de 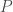 variables explicatives, également de n’importe quel format,
variables explicatives, également de n’importe quel format, 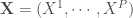 .
.
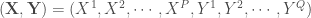 , avec
, avec 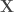 variables explicatives et
variables explicatives et 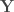 variables à prédire.
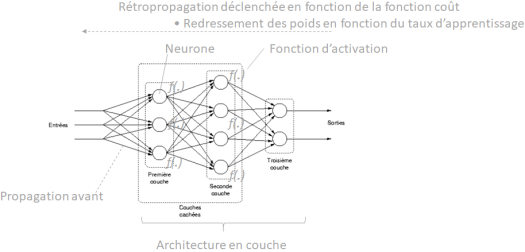
variables à prédire. 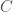 de couches cachées. Pour chaque couche
de couches cachées. Pour chaque couche 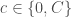 , on désigne un nombre de neurones
, on désigne un nombre de neurones  . On a volontairement mis la paramétrage possible à
. On a volontairement mis la paramétrage possible à 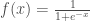 et de dérivée :
et de dérivée : 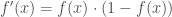 . Mais on en retrouve d’autres qui le sont également dans une moindre mesure,
. Mais on en retrouve d’autres qui le sont également dans une moindre mesure, , appréciée par sa simplicité et sa capacité à résourdre le problème du gradient pour certaines types de réseau. Sa dérivée est
, appréciée par sa simplicité et sa capacité à résourdre le problème du gradient pour certaines types de réseau. Sa dérivée est 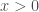 et
et 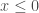 ;
;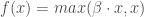 , variation de ReLU permettant l’utilisation d’un « petit » gradient lorsque l’entrée est négative. Sa dérivée est
, variation de ReLU permettant l’utilisation d’un « petit » gradient lorsque l’entrée est négative. Sa dérivée est 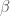 si
si 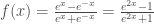 , similaire à la fonction sigmoïde mais bornée sur
, similaire à la fonction sigmoïde mais bornée sur ![[-1, 1]](https://s0.wp.com/latex.php?latex=%5B-1%2C+1%5D&bg=ffffff&fg=404040&s=0&c=20201002) , utile pour certains types de réseau nécessitant que les données soient normalisées. Sa dérivée est
, utile pour certains types de réseau nécessitant que les données soient normalisées. Sa dérivée est 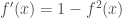 ;
;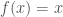 si
si 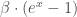 si
si 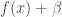 si
si  , à privilégier
, à privilégier 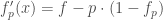 si
si 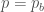 et
et  si
si  ;
;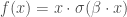 , avec
, avec  la fonction sigmoïde, permettant d’améliorer les performances dans certains cas de l’utilisation de la fonction ReLU. Sa dérivée est
la fonction sigmoïde, permettant d’améliorer les performances dans certains cas de l’utilisation de la fonction ReLU. Sa dérivée est 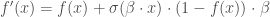 .
.![[0, 1]](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D&bg=ffffff&fg=404040&s=0&c=20201002) ou
ou ![[-1,1]](https://s0.wp.com/latex.php?latex=%5B-1%2C1%5D&bg=ffffff&fg=404040&s=0&c=20201002) afin de contrôler le calcul des poids, favorisant alors certaines variables au détriment de la qualité prédictive du modèle final.
afin de contrôler le calcul des poids, favorisant alors certaines variables au détriment de la qualité prédictive du modèle final.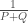 . Pour chacune des couches cachées
. Pour chacune des couches cachées ![c \in [1, C]](https://s0.wp.com/latex.php?latex=c+%5Cin+%5B1%2C+C%5D&bg=ffffff&fg=404040&s=0&c=20201002) , on notera
, on notera  la matrice des poids de taille
la matrice des poids de taille 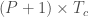 si
si  ,
, 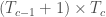 si
si ![c \in [2, C]](https://s0.wp.com/latex.php?latex=c+%5Cin+%5B2%2C+C%5D&bg=ffffff&fg=404040&s=0&c=20201002) . Enfin, il faut également attribuer à la couche de sortie ses propres pondérations
. Enfin, il faut également attribuer à la couche de sortie ses propres pondérations  , tirées de la même manière et de taille
, tirées de la même manière et de taille  . A noter que l’ajout de
. A noter que l’ajout de 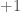 systématiquement est lié au besoin d’avoir, sans que cela soit obligatoire mais simplement conseillé, une ligne supplémentaire de poids associés aux termes constants.
systématiquement est lié au besoin d’avoir, sans que cela soit obligatoire mais simplement conseillé, une ligne supplémentaire de poids associés aux termes constants.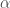 , qui servira à fixer la vitesse de correction des matrices de pondérations. Ce dernier étant un pourcentage, il doit être compris dans
, qui servira à fixer la vitesse de correction des matrices de pondérations. Ce dernier étant un pourcentage, il doit être compris dans 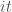 à appliquer afin d’arrêter l’algorithme qu’il converge ou non.
à appliquer afin d’arrêter l’algorithme qu’il converge ou non.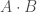 le produit matricielle, on applique l’algorithme suivant,
le produit matricielle, on applique l’algorithme suivant,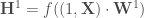 ;
;![\forall c \in [2, C], \mathbf{H} ^c = f((1,\mathbf{H} ^{c-1}) \cdot \mathbf{W} ^c)](https://s0.wp.com/latex.php?latex=%5Cforall+c+%5Cin+%5B2%2C+C%5D%2C+%5Cmathbf%7BH%7D+%5Ec+%3D+f%28%281%2C%5Cmathbf%7BH%7D+%5E%7Bc-1%7D%29+%5Ccdot+%5Cmathbf%7BW%7D+%5Ec%29&bg=ffffff&fg=404040&s=0&c=20201002) ;
;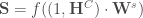
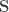 avec la réponse
avec la réponse 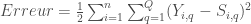 , le classique du genre. On peut précéder à sa variante consistant à appliquer le facteur
, le classique du genre. On peut précéder à sa variante consistant à appliquer le facteur 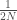 au lieu de
au lieu de  ou encore celle s’affranchissant de l’élévation au carré pour les valeurs absolues (MAE),
ou encore celle s’affranchissant de l’élévation au carré pour les valeurs absolues (MAE),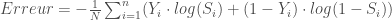 , réservée à une réponse univariée binaire et donc souvent associée à la fonction d’activation sigmoïde ;
, réservée à une réponse univariée binaire et donc souvent associée à la fonction d’activation sigmoïde ; , réservée à une réponse univariée à plusieurs classes
, réservée à une réponse univariée à plusieurs classes 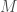 et donc souvent associée à la fonction d’activation softmax.
et donc souvent associée à la fonction d’activation softmax. le produit terme à terme,
le produit terme à terme,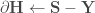 , sachant que certains réseaux programmés font intervenir la dérivée de la fonction coût à la place de la formule proposée ;
, sachant que certains réseaux programmés font intervenir la dérivée de la fonction coût à la place de la formule proposée ;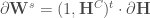
 , la matrice des poids de la couche de sortie est utilisée cette fois-ci en lui retirant la première ligne ;
, la matrice des poids de la couche de sortie est utilisée cette fois-ci en lui retirant la première ligne ;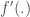 , et en notant
, et en notant  le produit terme à terme,
le produit terme à terme, 
![\forall c \in [C-1, \cdots, 2]](https://s0.wp.com/latex.php?latex=%5Cforall+c+%5Cin+%5BC-1%2C+%5Ccdots%2C+2%5D&bg=ffffff&fg=404040&s=0&c=20201002) ,
, , la matrice des poids de la couche
, la matrice des poids de la couche  est utilisée en lui ôtant la première ligne ;
est utilisée en lui ôtant la première ligne ;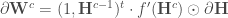
 , la matrice des poids de la seconde couche est utilisée en lui supprimant la première ligne ;
, la matrice des poids de la seconde couche est utilisée en lui supprimant la première ligne ;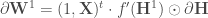
 . Et on applique ces corrections en une seule fois :
. Et on applique ces corrections en une seule fois : ![\forall c \in [1, \cdots, C, S], \mathbf{W} ^c \leftarrow \mathbf{W} ^c - \alpha \cdot \partial \mathbf{W} ^c](https://s0.wp.com/latex.php?latex=%5Cforall+c+%5Cin+%5B1%2C+%5Ccdots%2C+C%2C+S%5D%2C+%5Cmathbf%7BW%7D+%5Ec+%5Cleftarrow+%5Cmathbf%7BW%7D+%5Ec+-+%5Calpha+%5Ccdot+%5Cpartial+%5Cmathbf%7BW%7D+%5Ec&bg=ffffff&fg=404040&s=0&c=20201002)
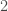 à
à 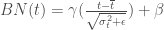
 paramètre d’échelle,
paramètre d’échelle,  constante ajoutée pour évitée la division par
constante ajoutée pour évitée la division par  et à chaque couche. Une fois de plus, le paramètre
et à chaque couche. Une fois de plus, le paramètre  avec
avec  distance euclidienne entre le point d’entrée et le centre et
distance euclidienne entre le point d’entrée et le centre et 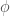 le paramètre de largeur gaussienne ou écart-type, et d’une couche de sortie. La notion de centre dans un RBF consiste à en définir un pour chaque neurone de la couche cachée, soit un point dans l’espace d’entrée du réseau.
le paramètre de largeur gaussienne ou écart-type, et d’une couche de sortie. La notion de centre dans un RBF consiste à en définir un pour chaque neurone de la couche cachée, soit un point dans l’espace d’entrée du réseau. 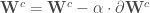
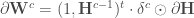
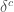 qui est l’erreur de prédiction et servira à ajuster et réajuster les matrices des poids de chaque couche. En notant
qui est l’erreur de prédiction et servira à ajuster et réajuster les matrices des poids de chaque couche. En notant 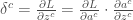
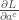 mesure comment le coût
mesure comment le coût  représente la dérivée de la fonction d’activation par rapport à son entrée. Cette dérivée mesure comment de petits changements dans l’entrée de la couche de sortie affectent la sortie elle-même.
représente la dérivée de la fonction d’activation par rapport à son entrée. Cette dérivée mesure comment de petits changements dans l’entrée de la couche de sortie affectent la sortie elle-même.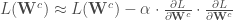
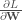 est faible, alors la mise à jour des poids est stable, tandis que si elle est importante, la mise à jour devient significative. Dès lors, le taux d’apprentissage va permettre un équilinre entre converge rapide et stabilité à l’entraînement.
est faible, alors la mise à jour des poids est stable, tandis que si elle est importante, la mise à jour devient significative. Dès lors, le taux d’apprentissage va permettre un équilinre entre converge rapide et stabilité à l’entraînement. suivant,
suivant,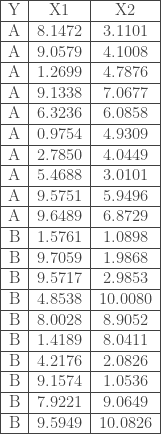
 . Comme il s’agit d’un exemple, on s’affranchira de la construction par apprentissage statistique. De plus, on ne procèdera pas à la standardisation des variables en amont.
. Comme il s’agit d’un exemple, on s’affranchira de la construction par apprentissage statistique. De plus, on ne procèdera pas à la standardisation des variables en amont.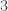 neurones et la seconde à
neurones et la seconde à 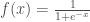 , de dérivée
, de dérivée 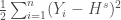 ;
;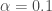 ;
;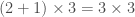 , nombre de neurones de la couche d’entrée, soit deux car deux variables explicatives et nombre de neurones paramétrée sur cette couche cachée :
, nombre de neurones de la couche d’entrée, soit deux car deux variables explicatives et nombre de neurones paramétrée sur cette couche cachée : 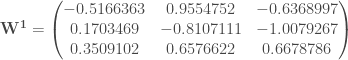
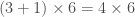 (nombre de neurones de la première couche cachée puis de la seconde couche) :
(nombre de neurones de la première couche cachée puis de la seconde couche) :
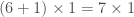 (nombre de neurones de la seconde et dernière couche et nombre de réponse de
(nombre de neurones de la seconde et dernière couche et nombre de réponse de 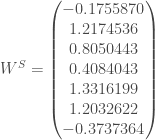

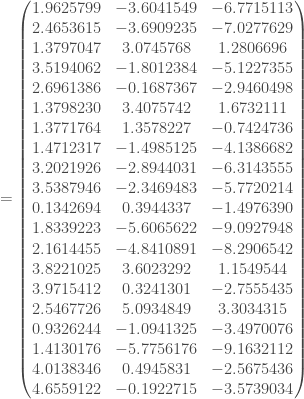
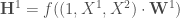
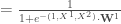
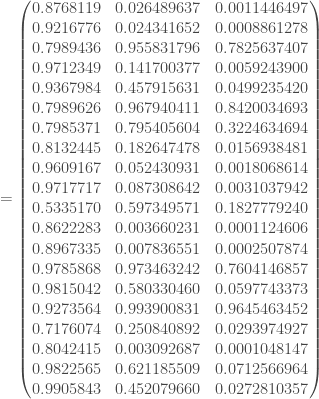
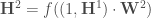

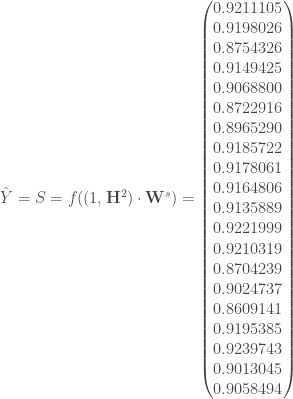
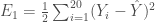
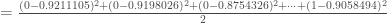
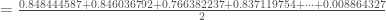
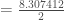
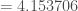

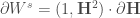


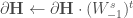


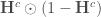 :
: 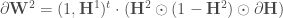


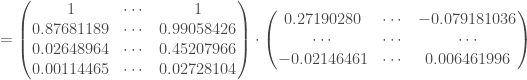


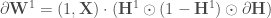
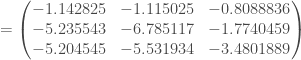
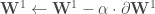
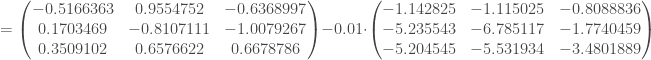
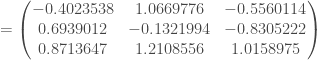
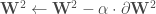

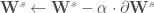

 vont changer, on obtiendra pour
vont changer, on obtiendra pour  itérations, la courbe de l’évolution de l’erreur de prédiction suivante :
itérations, la courbe de l’évolution de l’erreur de prédiction suivante :
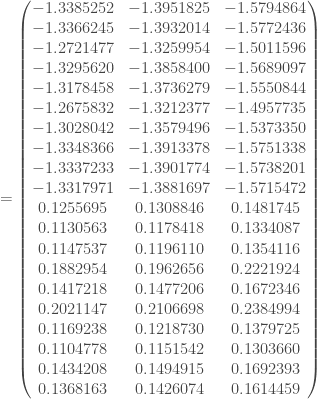
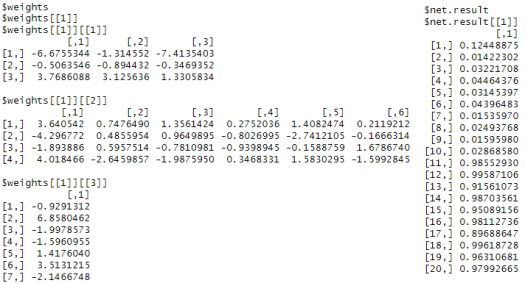
 itérations, l’algorithme converge. On a ainsi les pondérations finales suivantes :
itérations, l’algorithme converge. On a ainsi les pondérations finales suivantes :

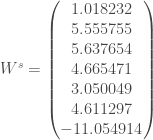
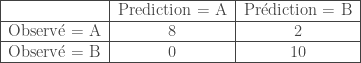
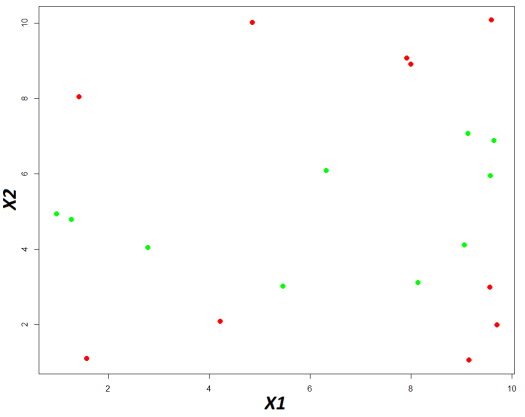
 . Enfin, et plus concrètement, on peut afficher le découpage du plan comparé aux classes réelles.
. Enfin, et plus concrètement, on peut afficher le découpage du plan comparé aux classes réelles.
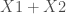 ;
;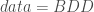 ;
;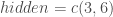 ;
;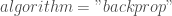 ;
;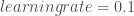 ;
;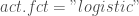 ;
;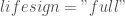 ;
;  .
.
 . Etant donné que l’on veut
. Etant donné que l’on veut  ;
;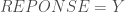 ;
;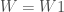
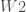
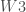 ;
; ;
;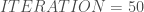 ;
;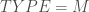 pour tuner les paramètres,
pour tuner les paramètres, 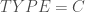 pour classer un nouvel individu.
pour classer un nouvel individu.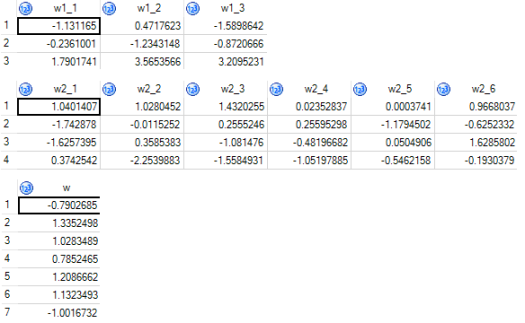


 itérations, réalisées en
itérations, réalisées en  minutes, très fortement dépendant de la taille de la base de données du fait de l’application du produit scalaire.
minutes, très fortement dépendant de la taille de la base de données du fait de l’application du produit scalaire.
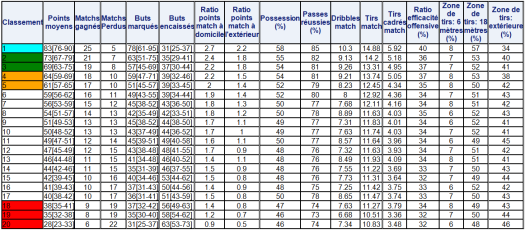
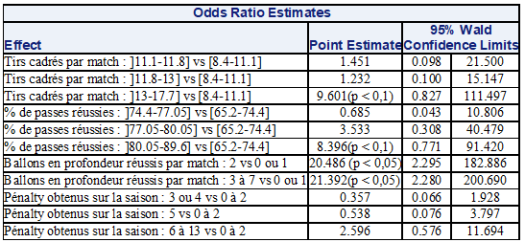
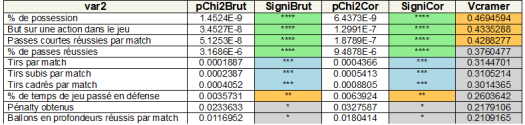
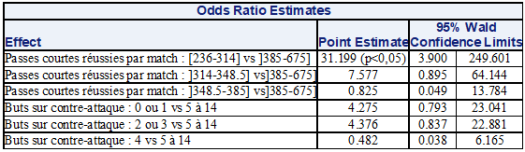
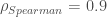 ), du taux de passes réussies (
), du taux de passes réussies (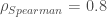 ) et le nombre moyen de tirs par match (
) et le nombre moyen de tirs par match (

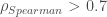 ) et se renforce nettement après les résultats de la 16ème journée (
) et se renforce nettement après les résultats de la 16ème journée (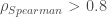 ). il faut alors attendre les résultats de la 26ème journée pour atteindre une corrélation quasi-parfaite (
). il faut alors attendre les résultats de la 26ème journée pour atteindre une corrélation quasi-parfaite (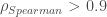 ).
).








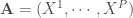 et
et  continues. Les deux blocs peuvent être appariés ou non appariés, l’outil étant efficace dans les deux cas.
continues. Les deux blocs peuvent être appariés ou non appariés, l’outil étant efficace dans les deux cas.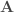 ,
, 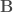 continues.
continues.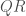 ) de
) de 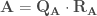

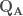 ,
, 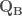 matrices orthogonales et
matrices orthogonales et 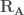 ,
,  matrices triangulaires supérieures. On utilisera ensuite la matrice
matrices triangulaires supérieures. On utilisera ensuite la matrice 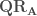 , respectivement
, respectivement  , dont le triangle supérieur contient
, dont le triangle supérieur contient 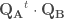
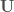 et
et 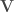 qui serviront à boucler les calculs.
qui serviront à boucler les calculs.



 ° entre deux blocs de variables implique une anti-corrélation entre eux ;
° entre deux blocs de variables implique une anti-corrélation entre eux ;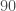 ° entre deux blocs de variables implique l’absence de corrélation entre eux.
° entre deux blocs de variables implique l’absence de corrélation entre eux. muni de la métrique
muni de la métrique 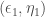 sous contrainte d’obtenir l’angle le plus petit et ensuite le couple
sous contrainte d’obtenir l’angle le plus petit et ensuite le couple 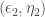
![(\epsilon_p, \eta_p), p \in [3, P]](https://s0.wp.com/latex.php?latex=%28%5Cepsilon_p%2C+%5Ceta_p%29%2C+p+%5Cin+%5B3%2C+P%5D&bg=ffffff&fg=404040&s=0&c=20201002) .
.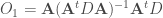 ,
, 
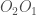 est diagonalisable, de valeurs propres
est diagonalisable, de valeurs propres 

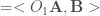

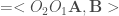
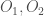 sont
sont ![\epsilon_p, \eta_p, p \in [1, P]](https://s0.wp.com/latex.php?latex=%5Cepsilon_p%2C+%5Ceta_p%2C+p+%5Cin+%5B1%2C+P%5D&bg=ffffff&fg=404040&s=0&c=20201002) ,
, 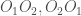 sont associés aux mêmes valeurs propres. De plus, ils s’expriment comme combinaisons linéaires de
sont associés aux mêmes valeurs propres. De plus, ils s’expriment comme combinaisons linéaires de  ,
, 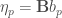 ,
, ![\forall p \in [1,P]](https://s0.wp.com/latex.php?latex=%5Cforall+p+%5Cin+%5B1%2CP%5D&bg=ffffff&fg=404040&s=0&c=20201002)
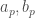 facteurs canoniques obtenus par,
facteurs canoniques obtenus par,![O_1 O_2 \epsilon_p = \lambda_p \epsilon_p, \forall p \in [1,P]](https://s0.wp.com/latex.php?latex=O_1+O_2+%5Cepsilon_p+%3D+%5Clambda_p+%5Cepsilon_p%2C+%5Cforall+p+%5Cin+%5B1%2CP%5D&bg=ffffff&fg=404040&s=0&c=20201002)
![\Longleftrightarrow O_1 O_2 \mathbf{A} a_1 = \lambda_p \mathbf{A} a_p, \forall p \in [1,P]](https://s0.wp.com/latex.php?latex=%5CLongleftrightarrow+O_1+O_2+%5Cmathbf%7BA%7D+a_1+%3D+%5Clambda_p+%5Cmathbf%7BA%7D+a_p%2C+%5Cforall+p+%5Cin+%5B1%2CP%5D&bg=ffffff&fg=404040&s=0&c=20201002)
![\Longleftrightarrow \mathbf{A} (\mathbf{A} ^t D \mathbf{A}) ^{-1} \mathbf{A} ^t D \mathbf{B} (\mathbf{B} ^t D \mathbf{B}) ^{-1} \mathbf{B} ^t D \mathbf{A} a_p = \lambda_p \mathbf{A} a_p, \forall p \in [1,P]](https://s0.wp.com/latex.php?latex=%5CLongleftrightarrow+%5Cmathbf%7BA%7D+%28%5Cmathbf%7BA%7D+%5Et+D+%5Cmathbf%7BA%7D%29+%5E%7B-1%7D+%5Cmathbf%7BA%7D+%5Et+D+%5Cmathbf%7BB%7D+%28%5Cmathbf%7BB%7D+%5Et+D+%5Cmathbf%7BB%7D%29+%5E%7B-1%7D+%5Cmathbf%7BB%7D+%5Et+D+%5Cmathbf%7BA%7D+a_p+%3D+%5Clambda_p+%5Cmathbf%7BA%7D+a_p%2C+%5Cforall+p+%5Cin+%5B1%2CP%5D&bg=ffffff&fg=404040&s=0&c=20201002)
![\mathbf{V_{1,1}} ^{-1} \mathbf{V_{1,2}} \mathbf{V_{2,2}} ^{-1} \mathbf{V_{2,1}} a_p = \lambda_p a_p, \forall p \in [1,P]](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BV_%7B1%2C1%7D%7D+%5E%7B-1%7D+%5Cmathbf%7BV_%7B1%2C2%7D%7D+%5Cmathbf%7BV_%7B2%2C2%7D%7D+%5E%7B-1%7D+%5Cmathbf%7BV_%7B2%2C1%7D%7D+a_p+%3D+%5Clambda_p+a_p%2C+%5Cforall+p+%5Cin+%5B1%2CP%5D&bg=ffffff&fg=404040&s=0&c=20201002)
![\mathbf{V_{2,2}} ^{-1} \mathbf{V_{2,1}} \mathbf{V_{1,1}} ^{-1} \mathbf{V_{1,2}} b_p = \lambda_p b_p, \forall p \in [1,P]](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BV_%7B2%2C2%7D%7D+%5E%7B-1%7D+%5Cmathbf%7BV_%7B2%2C1%7D%7D+%5Cmathbf%7BV_%7B1%2C1%7D%7D+%5E%7B-1%7D+%5Cmathbf%7BV_%7B1%2C2%7D%7D+b_p+%3D+%5Clambda_p+b_p%2C+%5Cforall+p+%5Cin+%5B1%2CP%5D&bg=ffffff&fg=404040&s=0&c=20201002)
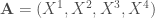 et
et 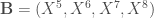 suivants à comparer,
suivants à comparer,
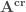 et
et 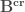 . Puis on calcule leur décomposition
. Puis on calcule leur décomposition 




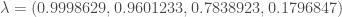
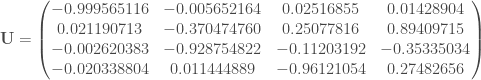
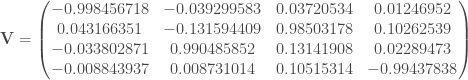
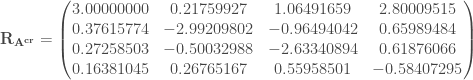



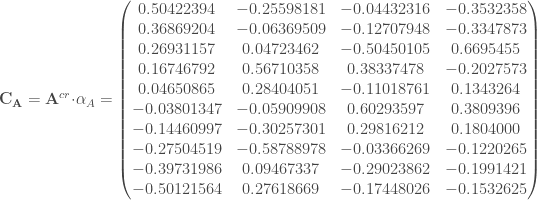
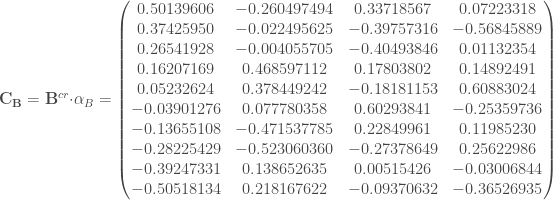



 ne sont pas assez proches du cercle de corrélation pour être interprétées.
ne sont pas assez proches du cercle de corrélation pour être interprétées. 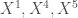 soit la possibilité de prédire
soit la possibilité de prédire  à partir d’une combinaison linéaire des variables
à partir d’une combinaison linéaire des variables  . Le second concerne les variables
. Le second concerne les variables 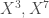 , soit un lien direct très fort entre elles.
, soit un lien direct très fort entre elles.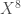 est anti-corrélée (angle de
est anti-corrélée (angle de ![x = E[,c("XA1", "XA2", "XA3", "XA4")]](https://s0.wp.com/latex.php?latex=x+%3D+E%5B%2Cc%28%22XA1%22%2C+%22XA2%22%2C+%22XA3%22%2C+%22XA4%22%29%5D&bg=ffffff&fg=404040&s=0&c=20201002) ;
;![y = E[,c("XB1", "XB2", "XB3", "XB4")]](https://s0.wp.com/latex.php?latex=y+%3D+E%5B%2Cc%28%22XB1%22%2C+%22XB2%22%2C+%22XB3%22%2C+%22XB4%22%29%5D&bg=ffffff&fg=404040&s=0&c=20201002) ;
; ;
; .
.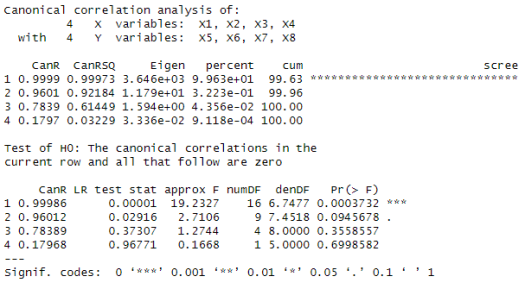
 les valeurs propres, qui sont les mêmes que celles obtenues lors des calculs manuels (cf partie « Exemple ») ;
les valeurs propres, qui sont les mêmes que celles obtenues lors des calculs manuels (cf partie « Exemple ») ; sur l’objet créé permet d’afficher les coefficients canoniques, qui diffèrent de ceux obtenus par les calculs manuels (cf partie « Exemple ») non pas par l’algorithme utilisé mais par la façon de centrer-réduire les données ;
sur l’objet créé permet d’afficher les coefficients canoniques, qui diffèrent de ceux obtenus par les calculs manuels (cf partie « Exemple ») non pas par l’algorithme utilisé mais par la façon de centrer-réduire les données ; , qui sont les mêmes que celles obtenues lors des calculs manuels (cf partie « Exemple »).
, qui sont les mêmes que celles obtenues lors des calculs manuels (cf partie « Exemple »).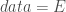 ;
;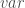

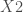
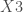
 ;
;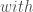
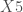
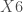
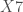
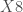 ;
;
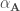 et
et  associée aux valeurs propres du premier tableau, qui diffèrent de celles obtenues lors des calculs manuels (cf partie « Exemple ») non pas par l’algorithme utilisé mais par la méthode pour centrer-réduire les données ;
associée aux valeurs propres du premier tableau, qui diffèrent de celles obtenues lors des calculs manuels (cf partie « Exemple ») non pas par l’algorithme utilisé mais par la méthode pour centrer-réduire les données ;
![\alpha_i ^*, i \in [1,n^*]](https://s0.wp.com/latex.php?latex=%5Calpha_i+%5E%2A%2C+i+%5Cin+%5B1%2Cn%5E%2A%5D&bg=ffffff&fg=404040&s=0&c=20201002) , qui ne correspondent donc pas aux
, qui ne correspondent donc pas aux 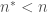 individus pour lesquels l’influence est significative (ceux associés à un vecteur support négligeable sont alors supprimés du modèle prédictif final).
individus pour lesquels l’influence est significative (ceux associés à un vecteur support négligeable sont alors supprimés du modèle prédictif final).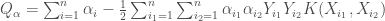
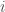 ème ligne est de la forme,
ème ligne est de la forme,![\alpha_i ^* = \frac{Q_{\alpha}}{\partial Q_{\alpha_i}} = \alpha_i - \frac{1}{2} \sum_{i_2 = 1} ^n \alpha_{i_2} Y_i Y_{i_2} K(X_i, X_{i_2}) = 1, \forall i \in [1,n]](https://s0.wp.com/latex.php?latex=%5Calpha_i+%5E%2A+%3D+%5Cfrac%7BQ_%7B%5Calpha%7D%7D%7B%5Cpartial+Q_%7B%5Calpha_i%7D%7D+%3D+%5Calpha_i+-+%5Cfrac%7B1%7D%7B2%7D+%5Csum_%7Bi_2+%3D+1%7D+%5En+%5Calpha_%7Bi_2%7D+Y_i+Y_%7Bi_2%7D+K%28X_i%2C+X_%7Bi_2%7D%29+%3D+1%2C+%5Cforall+i+%5Cin+%5B1%2Cn%5D&bg=ffffff&fg=404040&s=0&c=20201002)
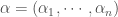 représente le vecteur des multiplicateurs de Lagrange.
représente le vecteur des multiplicateurs de Lagrange.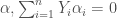 . Ce système est alors noté
. Ce système est alors noté  .
.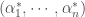 .
. soit les coefficients d’influence de nos vecteurs supports associés aux différentes observations. Cependant, les estimations
soit les coefficients d’influence de nos vecteurs supports associés aux différentes observations. Cependant, les estimations 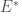 l’ensemble des observations associées à un vecteur support non nul et dont l’influence doit être considérée pour la prédiction. L’Équation de prédiction est alors,
l’ensemble des observations associées à un vecteur support non nul et dont l’influence doit être considérée pour la prédiction. L’Équation de prédiction est alors,
 le produit scalaire,
le produit scalaire,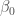 le coefficient constant obtenu par,
le coefficient constant obtenu par,
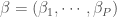 les coefficients obtenus par,
les coefficients obtenus par,![\forall p \in [1,P], \beta_p = \sum_{i = 1} ^n \alpha_i ^* X_i ^p](https://s0.wp.com/latex.php?latex=%5Cforall+p+%5Cin+%5B1%2CP%5D%2C+%5Cbeta_p+%3D+%5Csum_%7Bi+%3D+1%7D+%5En+%5Calpha_i+%5E%2A+X_i+%5Ep&bg=ffffff&fg=404040&s=0&c=20201002)
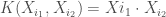
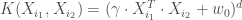 ,
,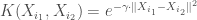 , avec,
, avec, 
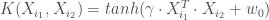 .
.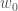 et
et  sont les paramètres à figer.
sont les paramètres à figer.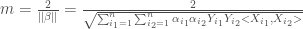
 qui est en fait le vecteur unitaire pondérant le noyau utilisé
qui est en fait le vecteur unitaire pondérant le noyau utilisé 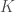 , le système à résoudre pour définir la sensibilité de la marge est alors,
, le système à résoudre pour définir la sensibilité de la marge est alors,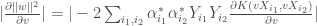
 classifieurs et d’avoir recours à un schéma de vote afin de décider de la classe de prédiction.
classifieurs et d’avoir recours à un schéma de vote afin de décider de la classe de prédiction.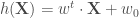
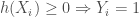 ,
,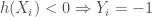 ,
,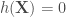 est un hyperplan, appelé hyperplan séparateur ou séparatrice. L’objectif est d’avoir,
est un hyperplan, appelé hyperplan séparateur ou séparatrice. L’objectif est d’avoir, ![\forall i \in [1,n], y_i \cdot h(X_i) \geq 0](https://s0.wp.com/latex.php?latex=%5Cforall+i+%5Cin+%5B1%2Cn%5D%2C+y_i+%5Ccdot+h%28X_i%29+%5Cgeq+0&bg=ffffff&fg=404040&s=0&c=20201002)
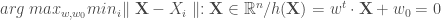
 à l’hyperplan est donnée par sa projection orthogonale sur l’hyperplan,
à l’hyperplan est donnée par sa projection orthogonale sur l’hyperplan,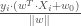
![arg \hspace*{1mm} max_{w,w_0} {\frac{1}{\parallel w \parallel} min_i [y_i \cdot (w^t \cdot X_i + w_0)]}](https://s0.wp.com/latex.php?latex=arg+%5Chspace%2A%7B1mm%7D+max_%7Bw%2Cw_0%7D+%7B%5Cfrac%7B1%7D%7B%5Cparallel+w+%5Cparallel%7D+min_i+%5By_i+%5Ccdot+%28w%5Et+%5Ccdot+X_i+%2B+w_0%29%5D%7D&bg=ffffff&fg=404040&s=0&c=20201002)
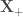 pour les vecteurs supports sur la frontière positive, et
pour les vecteurs supports sur la frontière positive, et 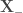 pour ceux situés sur la frontière opposée) satisfassent,
pour ceux situés sur la frontière opposée) satisfassent, 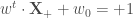
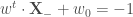
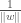 . La formulation dite primale des SVM est ainsi,
. La formulation dite primale des SVM est ainsi, sous contraintes que
sous contraintes que 
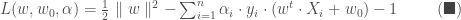
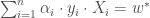

 , nous avons la formulation duale suivante,
, nous avons la formulation duale suivante,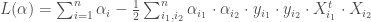
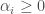 , et
, et 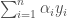 .
.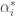 . L’Equation de l’hyperplan solution devient alors,
. L’Equation de l’hyperplan solution devient alors, 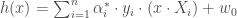
 .
.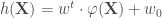
![\forall i \in [1,n], y_i \cdot h(X_i) > 0](https://s0.wp.com/latex.php?latex=%5Cforall+i+%5Cin+%5B1%2Cn%5D%2C+y_i+%5Ccdot+h%28X_i%29+%3E+0&bg=ffffff&fg=404040&s=0&c=20201002) .
.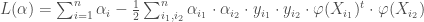
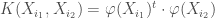
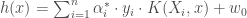
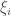 , qui permettent de relâcher les contraintes sur les vecteurs d’apprentissage:
, qui permettent de relâcher les contraintes sur les vecteurs d’apprentissage: ![\forall \xi_i \geq 0, i \in [1,n], y_i \cdot (w^t \cdot X_i + w_0) \geq 1 - \xi_i](https://s0.wp.com/latex.php?latex=%5Cforall+%5Cxi_i+%5Cgeq+0%2C+i+%5Cin+%5B1%2Cn%5D%2C+y_i+%5Ccdot+%28w%5Et+%5Ccdot+X_i+%2B+w_0%29+%5Cgeq+1+-+%5Cxi_i&bg=ffffff&fg=404040&s=0&c=20201002)

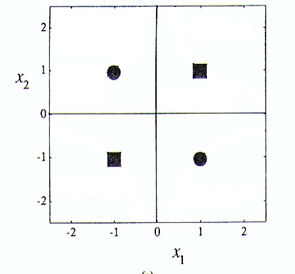
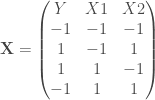
 et de paramètre
et de paramètre 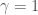 ,
,
 ,
,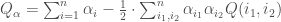
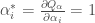
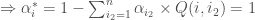
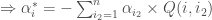
 en fonction de
en fonction de  . Nous obtenons alors la matrice,
. Nous obtenons alors la matrice,
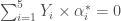 , nous rajoutons la condition au système à résoudre ainsi que la valeur de l’égalité (qui vaut
, nous rajoutons la condition au système à résoudre ainsi que la valeur de l’égalité (qui vaut 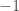 car, pour respecter le passage des équations à la forme matricielle du problème, nous faisons pivoter le coefficient constant associé à la somme des
car, pour respecter le passage des équations à la forme matricielle du problème, nous faisons pivoter le coefficient constant associé à la somme des 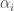 à droite),
à droite),
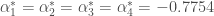
 . Nous calculons dans un premier temps les coefficients
. Nous calculons dans un premier temps les coefficients 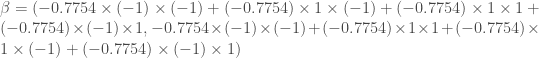
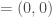
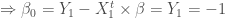
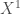 sur la base du modèle construit,
sur la base du modèle construit,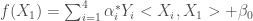

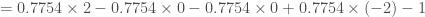
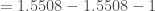
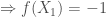
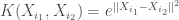
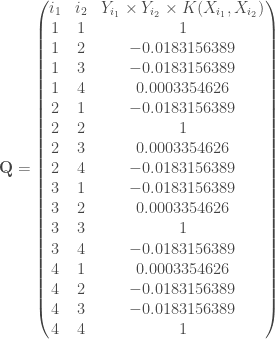
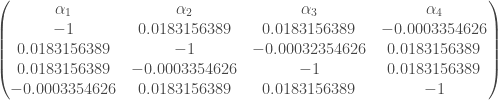


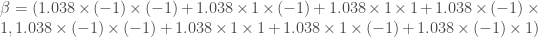
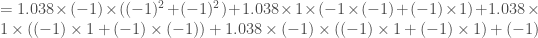



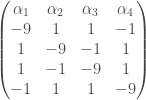
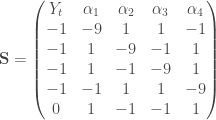
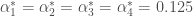

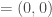


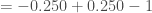

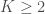 classes à partir d’une matrice de variables qualitatives
classes à partir d’une matrice de variables qualitatives  .
.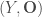 et sélectionner les axes non nuls et ainsi que ceux séparant au mieux les groupes de
et sélectionner les axes non nuls et ainsi que ceux séparant au mieux les groupes de 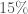 puis
puis 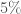 en fonction du nombre d’axes retenus. Suite à ce premier filtre appliqué,
en fonction du nombre d’axes retenus. Suite à ce premier filtre appliqué, 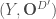 ,
,  ensemble des axes factorielles retenus.
ensemble des axes factorielles retenus.](https://s0.wp.com/latex.php?latex=%5Blatex%5D%28Y%2C%5Cmathbf%7BO%7D+%5E%7BD%27%7D%29&bg=ffffff&fg=404040&s=0&c=20201002) en retirant une par une les variables dont la p-valeur est la plus forte et en usant du critère de l'Aire (AUC), du volume (VUS) ou hypervolume (HUM) sous la Courbe ROC (AUC) en fonction du nombre de classe de
en retirant une par une les variables dont la p-valeur est la plus forte et en usant du critère de l'Aire (AUC), du volume (VUS) ou hypervolume (HUM) sous la Courbe ROC (AUC) en fonction du nombre de classe de 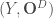
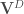 et en multipliant les coordonnées de nos modalités de variables par les coefficients respectifs à chacun de ces axes et obtenus en étape 4. La règle décisionnelle est alors de la forme suivante,
et en multipliant les coordonnées de nos modalités de variables par les coefficients respectifs à chacun de ces axes et obtenus en étape 4. La règle décisionnelle est alors de la forme suivante,
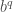 les composantes de l'ACM et
les composantes de l'ACM et  les valeurs propres qui leur sont associés. L'Une des formidables propriétés des axes factoriels construis via une ACM est qu'ils sont orthogonaux, rendant l'inversion des matrices nécessaires au calcul possible comparé au cas où nous aurions directement travaillé sur le tableau disjonctif complet. Nous pouvons alors obtenir le score
les valeurs propres qui leur sont associés. L'Une des formidables propriétés des axes factoriels construis via une ACM est qu'ils sont orthogonaux, rendant l'inversion des matrices nécessaires au calcul possible comparé au cas où nous aurions directement travaillé sur le tableau disjonctif complet. Nous pouvons alors obtenir le score 
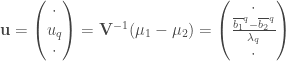
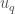 des coordonnées de ses catégories. En effet, nous avons
des coordonnées de ses catégories. En effet, nous avons 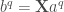 , où
, où  vecteur des coordonnées des modalités dans le plan factoriel. Nous avons alors,
vecteur des coordonnées des modalités dans le plan factoriel. Nous avons alors,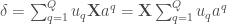

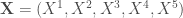 et sortons les coordonnées de nos individus sur les axes factoriels conçus,
et sortons les coordonnées de nos individus sur les axes factoriels conçus,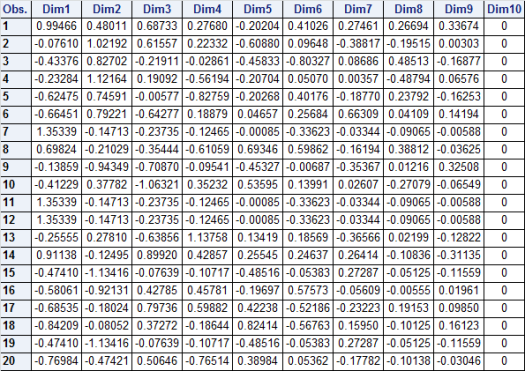
 .
. . Nous utilisons pour cela le test du
. Nous utilisons pour cela le test du 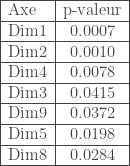
 , sept axes sont significatifs. Par conséquent, nous les conservons tous à cette étape. Appliquons maintenant un second filtre basé sur l'AUC. Nous obtenons alors,
, sept axes sont significatifs. Par conséquent, nous les conservons tous à cette étape. Appliquons maintenant un second filtre basé sur l'AUC. Nous obtenons alors,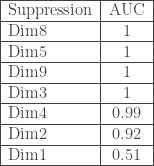
 puisque sur le modèle
puisque sur le modèle  , l'AUC reste maximale.
, l'AUC reste maximale. 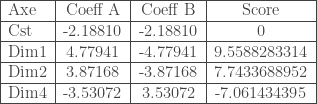
 ,
,

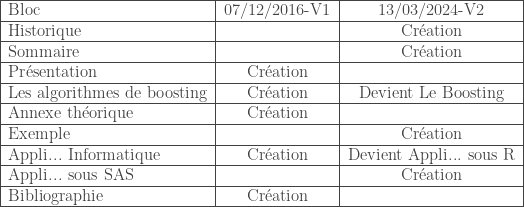
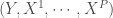 et d’établir la classification finale au travers d’un vote global pondéré. Chaque partie du plan se voit alors attribuer une pondération en fonction de sa performance de discrimination mise à jour itération par itération afin d’adapter la frontière décisionnelle en fonction des zones les plus difficiles à classer.
et d’établir la classification finale au travers d’un vote global pondéré. Chaque partie du plan se voit alors attribuer une pondération en fonction de sa performance de discrimination mise à jour itération par itération afin d’adapter la frontière décisionnelle en fonction des zones les plus difficiles à classer.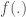 , une fonction de coût
, une fonction de coût 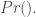 , un nombre
, un nombre 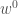 les poids d’origine que l’on fixe à la même valeur quelque soit l’observation.
les poids d’origine que l’on fixe à la même valeur quelque soit l’observation.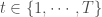 ,
,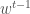 .
.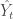 . Point important, si l’on ne souhaite pas utiliser d’apprentissage statistique alors ces deux premières étapes sont réalisées en même temps, on lance le classifieur faible directement en prenant en compte les
. Point important, si l’on ne souhaite pas utiliser d’apprentissage statistique alors ces deux premières étapes sont réalisées en même temps, on lance le classifieur faible directement en prenant en compte les ![\epsilon_t = Pr(I_{[\hat{Y_t} \neq Y]})](https://s0.wp.com/latex.php?latex=%5Cepsilon_t+%3D+Pr%28I_%7B%5B%5Chat%7BY_t%7D+%5Cneq+Y%5D%7D%29&bg=ffffff&fg=404040&s=0&c=20201002) .
.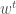 .
.![\hat{Y}_t, \forall t \in [1,T]](https://s0.wp.com/latex.php?latex=%5Chat%7BY%7D_t%2C+%5Cforall+t+%5Cin+%5B1%2CT%5D&bg=ffffff&fg=404040&s=0&c=20201002)
![w_i ^0 = \frac{1}{n}, \forall i \in [1,n]](https://s0.wp.com/latex.php?latex=w_i+%5E0+%3D+%5Cfrac%7B1%7D%7Bn%7D%2C+%5Cforall+i+%5Cin+%5B1%2Cn%5D&bg=ffffff&fg=404040&s=0&c=20201002)
![\forall t \in [1,T]](https://s0.wp.com/latex.php?latex=%5Cforall+t+%5Cin+%5B1%2CT%5D&bg=ffffff&fg=404040&s=0&c=20201002)
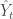 en prenant en compte les poids
en prenant en compte les poids 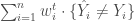 ;
;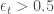 alors le classifieur fait mieux qu’une règle aléatoire et on conserve le modèle, sinon on ajuste,
alors le classifieur fait mieux qu’une règle aléatoire et on conserve le modèle, sinon on ajuste,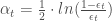
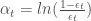
![w_i ^t = w_i ^{t - 1} e ^{\alpha_t \cdot I_{(\hat{Y}_i \neq Y_i)}}, \forall i \in [1,n]](https://s0.wp.com/latex.php?latex=w_i+%5Et+%3D+w_i+%5E%7Bt+-+1%7D+e+%5E%7B%5Calpha_t+%5Ccdot+I_%7B%28%5Chat%7BY%7D_i+%5Cneq+Y_i%29%7D%7D%2C+%5Cforall+i+%5Cin+%5B1%2Cn%5D&bg=ffffff&fg=404040&s=0&c=20201002)
![H(x) = sign[\sum_{t = 1} ^T \alpha_t f_t (x)]](https://s0.wp.com/latex.php?latex=H%28x%29+%3D+sign%5B%5Csum_%7Bt+%3D+1%7D+%5ET+%5Calpha_t+f_t+%28x%29%5D&bg=ffffff&fg=404040&s=0&c=20201002)
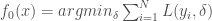 , avec
, avec ![t \in [1, T]](https://s0.wp.com/latex.php?latex=t+%5Cin+%5B1%2C+T%5D&bg=ffffff&fg=404040&s=0&c=20201002) ,
,![i \in [1, n]](https://s0.wp.com/latex.php?latex=i+%5Cin+%5B1%2C+n%5D&bg=ffffff&fg=404040&s=0&c=20201002) calculer,
calculer,![r_{i,t} = - [\frac{\partial L(y_i, f(x_i))}{\partial f(x_i)}]_{f = f_{t - 1}}](https://s0.wp.com/latex.php?latex=r_%7Bi%2Ct%7D+%3D+-+%5B%5Cfrac%7B%5Cpartial+L%28y_i%2C+f%28x_i%29%29%7D%7B%5Cpartial+f%28x_i%29%7D%5D_%7Bf+%3D+f_%7Bt+-+1%7D%7D&bg=ffffff&fg=404040&s=0&c=20201002)
 et donnant les régions décisionnelles
et donnant les régions décisionnelles 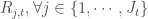
 , calculer,
, calculer,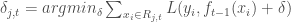
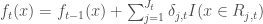
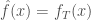
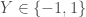 , on montre facilement que,
, on montre facilement que,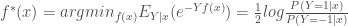
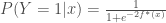
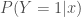 . Ce qui justifie l’usage de son signe comme règle de classification décrite par la formule,
. Ce qui justifie l’usage de son signe comme règle de classification décrite par la formule,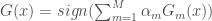
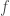 comme une transformation logit. On a,
comme une transformation logit. On a,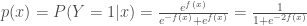
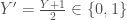 . La fonction de perte est alors,
. La fonction de perte est alors,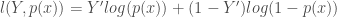

![E_{Y|x} [-l(Y,f(x))] = E_{Y|x} [e ^{-Y f(x)}]](https://s0.wp.com/latex.php?latex=E_%7BY%7Cx%7D+%5B-l%28Y%2Cf%28x%29%29%5D+%3D+E_%7BY%7Cx%7D+%5Be+%5E%7B-Y+f%28x%29%7D%5D&bg=ffffff&fg=404040&s=0&c=20201002)
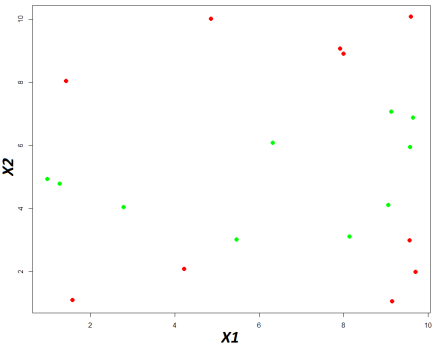
 observations ;
observations ;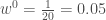 pour chaque observation ;
pour chaque observation ; . On obtient le modèle suivant :
. On obtient le modèle suivant :


 lorsque prédiction pour l’observation
lorsque prédiction pour l’observation 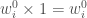 lorsque c’est le cas.
lorsque c’est le cas.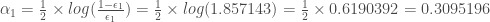

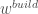 par :
par :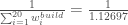

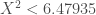 , ainsi que les mêmes performances.
, ainsi que les mêmes performances. 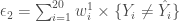

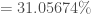

 ,
, 



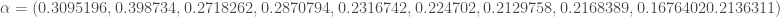


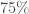 . Enfin, et plus concrètement, on peut afficher le découpage du plan comparé aux classes réelles.
. Enfin, et plus concrètement, on peut afficher le découpage du plan comparé aux classes réelles.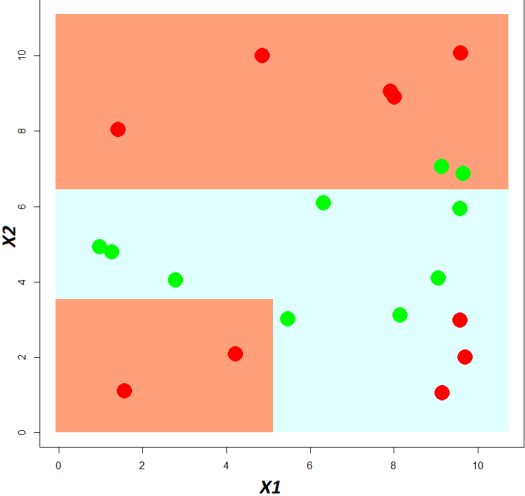
 ;
; ;
; ;
;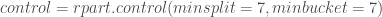 .
.
![\$trees[[.]]](https://s0.wp.com/latex.php?latex=%5C%24trees%5B%5B.%5D%5D&bg=ffffff&fg=404040&s=0&c=20201002) , les différents arbres de décisions conçus à chaque itération (on a volontairement tronqué la sortie), et qui sont les mêmes que ceux obtenus lors des calculs manuls (cf partie « Exemple ») ;
, les différents arbres de décisions conçus à chaque itération (on a volontairement tronqué la sortie), et qui sont les mêmes que ceux obtenus lors des calculs manuls (cf partie « Exemple ») ; à chaque itération :
à chaque itération :  , qui sont les mêmes que celles obtenues lors des calculs manuls (cf partie « Exemple ») ;
, qui sont les mêmes que celles obtenues lors des calculs manuls (cf partie « Exemple ») ; (la sortie
(la sortie  étant le résultat de chaque valeur divisé par la somme en ligne), qui sont les mêmes que ceux obtenus lors des calculs manuls (cf partie « Exemple ») ;
étant le résultat de chaque valeur divisé par la somme en ligne), qui sont les mêmes que ceux obtenus lors des calculs manuls (cf partie « Exemple ») ;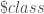 , qui sont les mêmes que celles obtenues lors des calculs manuls (cf partie « Exemple ») ;
, qui sont les mêmes que celles obtenues lors des calculs manuls (cf partie « Exemple ») ;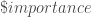 ;
;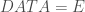 ;
; ;
; ;
;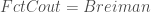 ;
;


 de bonne classification, contre
de bonne classification, contre 

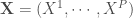 transformées en amont. Dès lors, on chercher déterminer un jeu de fonction :
transformées en amont. Dès lors, on chercher déterminer un jeu de fonction : 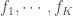 travaillant chacune sur une variable unique (
travaillant chacune sur une variable unique ( mais aussi sur des combinaisons de deux ou plusieurs autres (
mais aussi sur des combinaisons de deux ou plusieurs autres ( ). Le terme « Additif » vient du fait qu’il s’agira ensuite de sommer ces fonctions de transformation pour poser le modèle finale.
). Le terme « Additif » vient du fait qu’il s’agira ensuite de sommer ces fonctions de transformation pour poser le modèle finale.![E[Y | X ^1, \dots, X ^P] = \alpha + \sum_{p = 1} ^P f_p (X ^p) + \sum_{k = 1} ^K f_k (X ^{p_1}, \cdots)](https://s0.wp.com/latex.php?latex=E%5BY+%7C+X+%5E1%2C+%5Cdots%2C+X+%5EP%5D+%3D+%5Calpha+%2B+%5Csum_%7Bp+%3D+1%7D+%5EP+f_p+%28X+%5Ep%29+%2B+%5Csum_%7Bk+%3D+1%7D+%5EK+f_k+%28X+%5E%7Bp_1%7D%2C+%5Ccdots%29&bg=ffffff&fg=404040&s=0&c=20201002)
 , fonctions de transformation associée à la variable
, fonctions de transformation associée à la variable 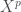 ou à un uplet de variables explicatives
ou à un uplet de variables explicatives 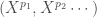 que l’on cherche à combiner directement.
que l’on cherche à combiner directement.![f_0 = E[Y] = \frac{1}{n} \sum_{i = 1} ^n Y_i](https://s0.wp.com/latex.php?latex=f_0+%3D+E%5BY%5D+%3D+%5Cfrac%7B1%7D%7Bn%7D+%5Csum_%7Bi+%3D+1%7D+%5En+Y_i&bg=ffffff&fg=404040&s=0&c=20201002) , et
, et ![f_p ^0 = 0, \forall p \in[1, P]](https://s0.wp.com/latex.php?latex=f_p+%5E0+%3D+0%2C+%5Cforall+p+%5Cin%5B1%2C+P%5D&bg=ffffff&fg=404040&s=0&c=20201002)
![p \in [1,P]](https://s0.wp.com/latex.php?latex=p+%5Cin+%5B1%2CP%5D&bg=ffffff&fg=404040&s=0&c=20201002) , déterminer,
, déterminer,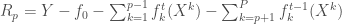
![f_p ^t = E[R_p | X ^p]](https://s0.wp.com/latex.php?latex=f_p+%5Et+%3D+E%5BR_p+%7C+X+%5Ep%5D&bg=ffffff&fg=404040&s=0&c=20201002)
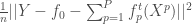 décroît ou satisfait le critère de convergence
décroît ou satisfait le critère de convergence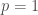
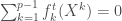
 le terme,
le terme,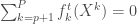
 , se fait selon la fonction lien retenue (modèle linéaire, logistique, etc).
, se fait selon la fonction lien retenue (modèle linéaire, logistique, etc).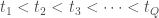 d’indice de parcours
d’indice de parcours 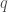
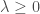 :
: ![CSS_q(X) = \sum_{i = 1} ^n [Y_i - g_q (X_i)] ^2 + \lambda \int_{[t_q, t_{q+1}]} (g_q '' (x)) ^2 dx](https://s0.wp.com/latex.php?latex=CSS_q%28X%29+%3D+%5Csum_%7Bi+%3D+1%7D+%5En+%5BY_i+-+g_q+%28X_i%29%5D+%5E2+%2B+%5Clambda+%5Cint_%7B%5Bt_q%2C+t_%7Bq%2B1%7D%5D%7D+%28g_q+%27%27+%28x%29%29+%5E2+dx&bg=ffffff&fg=404040&s=0&c=20201002)
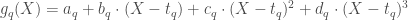 et
et 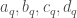 des coefficients constants à fixer au préalable. A noter que
des coefficients constants à fixer au préalable. A noter que  si
si ![X_i \not in ]t_q, t_{q+1}[](https://s0.wp.com/latex.php?latex=X_i+%5Cnot+in+%5Dt_q%2C+t_%7Bq%2B1%7D%5B&bg=ffffff&fg=404040&s=0&c=20201002) .
.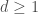 degrés du polynôme local et
degrés du polynôme local et 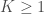 degrés de liberté :
degrés de liberté :![\forall k \in [1, K], B_{k,d} (X) = \frac{(X - t_k)}{(t_{k + d} - t_{k})} \cdot B_{k, d-1} (X) + \frac{t_{k+d+1} - X}{t_{k+d+1} - t_{k+1}} \cdot B_{k+1,d-1} (X)](https://s0.wp.com/latex.php?latex=%5Cforall+k+%5Cin+%5B1%2C+K%5D%2C+B_%7Bk%2Cd%7D+%28X%29+%3D+%5Cfrac%7B%28X+-+t_k%29%7D%7B%28t_%7Bk+%2B+d%7D+-+t_%7Bk%7D%29%7D+%5Ccdot+B_%7Bk%2C+d-1%7D+%28X%29+%2B+%5Cfrac%7Bt_%7Bk%2Bd%2B1%7D+-+X%7D%7Bt_%7Bk%2Bd%2B1%7D+-+t_%7Bk%2B1%7D%7D+%5Ccdot+B_%7Bk%2B1%2Cd-1%7D+%28X%29&bg=ffffff&fg=404040&s=0&c=20201002)
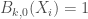 si
si 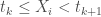 ,
, 
 ,
, 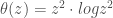 et
et  coefficients de régression à paramétrer. A noter que
coefficients de régression à paramétrer. A noter que ![f(x) = \sum_{k=1} ^K \beta_k \cdot B_{k,d} (X) + \lambda \int [f''(X)]^2 dx](https://s0.wp.com/latex.php?latex=f%28x%29+%3D+%5Csum_%7Bk%3D1%7D+%5EK+%5Cbeta_k+%5Ccdot+B_%7Bk%2Cd%7D+%28X%29+%2B+%5Clambda+%5Cint+%5Bf%27%27%28X%29%5D%5E2+dx&bg=ffffff&fg=404040&s=0&c=20201002)
 fonction B-splines déjà définie précédemment et
fonction B-splines déjà définie précédemment et  :
: ![LOESS(X) = min_{\alpha(x_0), \beta(x_0)} \sum_{i = 1} ^n K (x_0, X_i) \cdot [Y_i - \alpha(x_0) - \beta(x_0) \cdot X_i] ^2](https://s0.wp.com/latex.php?latex=LOESS%28X%29+%3D+min_%7B%5Calpha%28x_0%29%2C+%5Cbeta%28x_0%29%7D+%5Csum_%7Bi+%3D+1%7D+%5En+K+%28x_0%2C+X_i%29+%5Ccdot+%5BY_i+-+%5Calpha%28x_0%29+-+%5Cbeta%28x_0%29+%5Ccdot+X_i%5D+%5E2&bg=ffffff&fg=404040&s=0&c=20201002)
 coefficients à paramétrer.
coefficients à paramétrer.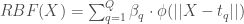
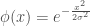 ,
,  paramètre de contrôle de la largeur de la fonction gaussienne.
paramètre de contrôle de la largeur de la fonction gaussienne.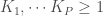 degrés de liberté :
degrés de liberté :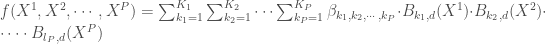
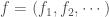 .
.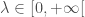 :
:![RSS(f,\lambda) = \sum_{i = 1} ^n [y_i - f(x_i)] ^2 + \lambda \int (f '' (t)) ^2 dt](https://s0.wp.com/latex.php?latex=RSS%28f%2C%5Clambda%29+%3D+%5Csum_%7Bi+%3D+1%7D+%5En+%5By_i+-+f%28x_i%29%5D+%5E2+%2B+%5Clambda+%5Cint+%28f+%27%27+%28t%29%29+%5E2+dt&bg=ffffff&fg=404040&s=0&c=20201002)
 alors
alors  , alors
, alors 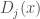 un sous-ensemble de
un sous-ensemble de 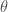 un vecteur de paramètres à estimer. La fonction d’origine peut alors se réécrire :
un vecteur de paramètres à estimer. La fonction d’origine peut alors se réécrire :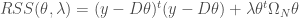
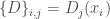 et
et 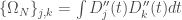 . La solution est alors,
. La solution est alors,

![min_{\alpha(x_0), \beta(x_0)} \sum_{i = 1} ^n K_{\lambda} (x_0,x_i) [y_i - \alpha(x_0) - \beta(x_0) x_i] ^2](https://s0.wp.com/latex.php?latex=min_%7B%5Calpha%28x_0%29%2C+%5Cbeta%28x_0%29%7D+%5Csum_%7Bi+%3D+1%7D+%5En+K_%7B%5Clambda%7D+%28x_0%2Cx_i%29+%5By_i+-+%5Calpha%28x_0%29+-+%5Cbeta%28x_0%29+x_i%5D+%5E2&bg=ffffff&fg=404040&s=0&c=20201002)
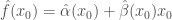
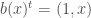 ,
,  composée des
composée des 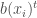 et
et 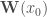 la matrice diagonale de taille
la matrice diagonale de taille 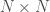 et dont l’élément
et dont l’élément 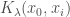 . On a alors,
. On a alors,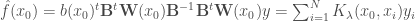

 et
et 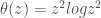 .
.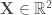 et les fonctions de base de la forme
et les fonctions de base de la forme 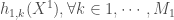 des coordonnées de
des coordonnées de  . Nous définissons alors,
. Nous définissons alors,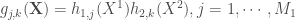 et
et 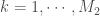
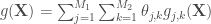
![min_J \sum_{i = 1} ^N \lbrace y_i - f(x_i) \rbrace ^2 + \lambda J[f]](https://s0.wp.com/latex.php?latex=min_J+%5Csum_%7Bi+%3D+1%7D+%5EN+%5Clbrace+y_i+-+f%28x_i%29+%5Crbrace+%5E2+%2B+%5Clambda+J%5Bf%5D&bg=ffffff&fg=404040&s=0&c=20201002)
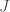 fonction de pénalisation visant à stabiliser
fonction de pénalisation visant à stabiliser 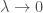 alors la solution s’approche d’une fonction d’interpolation et si
alors la solution s’approche d’une fonction d’interpolation et si 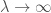 alors elle s’approche d’un plan des moindres carrés. Pour les valeurs intermédiaires de
alors elle s’approche d’un plan des moindres carrés. Pour les valeurs intermédiaires de 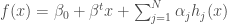
 et
et 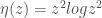 .
.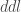 ) et
) et 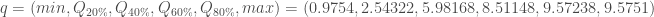
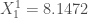 , ce qui implique que l’on va devoir développer cinq composantes.
, ce qui implique que l’on va devoir développer cinq composantes. 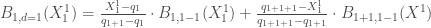
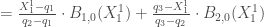
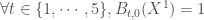 si
si 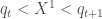 ,
, 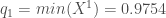 ,
, 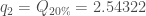 .et
.et 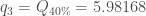 .
.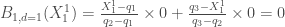
![X_1 ^1 = 8.1472 \notin ]0.9754, 2.54322[](https://s0.wp.com/latex.php?latex=X_1+%5E1+%3D+8.1472+%5Cnotin+%5D0.9754%2C+2.54322%5B&bg=ffffff&fg=404040&s=0&c=20201002) et
et ![\notin ]2.54322, 5.98168[](https://s0.wp.com/latex.php?latex=%5Cnotin+%5D2.54322%2C+5.98168%5B&bg=ffffff&fg=404040&s=0&c=20201002) .
. :
: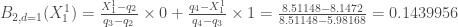
![X_1 ^1 = 8.1472 \notin ]2.54322, 5.98168[](https://s0.wp.com/latex.php?latex=X_1+%5E1+%3D+8.1472+%5Cnotin+%5D2.54322%2C+5.98168%5B&bg=ffffff&fg=404040&s=0&c=20201002) et
et ![\in ]5.98168, 8.51148[](https://s0.wp.com/latex.php?latex=%5Cin+%5D5.98168%2C+8.51148%5B&bg=ffffff&fg=404040&s=0&c=20201002) .
.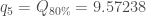 :
: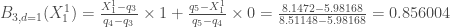
![X_1 ^1 = 8.1472 \in ]5.98168, 8.51148[](https://s0.wp.com/latex.php?latex=X_1+%5E1+%3D+8.1472+%5Cin+%5D5.98168%2C+8.51148%5B&bg=ffffff&fg=404040&s=0&c=20201002) et
et ![\notin ]8.51148, 9.57238[](https://s0.wp.com/latex.php?latex=%5Cnotin+%5D8.51148%2C+9.57238%5B&bg=ffffff&fg=404040&s=0&c=20201002) .
.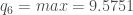 :
:
![X_1 ^1 = 8.1472 \notin ]8.51148, 9.57238[](https://s0.wp.com/latex.php?latex=X_1+%5E1+%3D+8.1472+%5Cnotin+%5D8.51148%2C+9.57238%5B&bg=ffffff&fg=404040&s=0&c=20201002) et
et ![\notin ]9.57238, 9.5751[](https://s0.wp.com/latex.php?latex=%5Cnotin+%5D9.57238%2C+9.5751%5B&bg=ffffff&fg=404040&s=0&c=20201002) .
.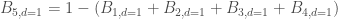
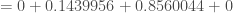

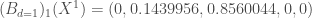

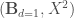 afin de déterminer les coefficients associés aux composantes B-spline de
afin de déterminer les coefficients associés aux composantes B-spline de  .
. 

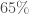 . Enfin, et plus concrètement, on peut afficher le découpage du plan comparé aux classes réelles.
. Enfin, et plus concrètement, on peut afficher le découpage du plan comparé aux classes réelles.
 , on remarquera que cette dernière contient directement l’application de la fonction de lissage (ici une B-spline) sur
, on remarquera que cette dernière contient directement l’application de la fonction de lissage (ici une B-spline) sur 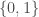 ;
;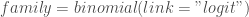 ;
;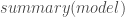 .
.
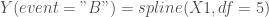
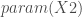 , on remarquera que cette dernière contient directement l’application de la fonction de lissage (ici une spline) sur
, on remarquera que cette dernière contient directement l’application de la fonction de lissage (ici une spline) sur 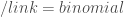 ;
;
