

Rob Tibshirani (à gauche) et Trevor Hastie (à droite)


- Présentation
- Le Modèle Additif Généralisé
- L’algorithme Back-fitting
- Les transformations
- Annexe théorique
- Exemple
- Application informatique
- Bibliographie
Le Modèle Additif Généralisé (GAM), élaboré par Trevor Hastie et Rob Tibshirani en 1990, est un outil permettant de discriminer une variable 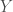
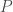
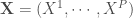
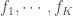


Le modèle GAM nécessite un jeu d’apprentissage pour sa construction et un jeu de test pour sa validation car il est sujet au sur-apprentissage du fait des fonctions de transformation utilisées particulièrement puissantes. En dépit de sa grande capacité avérée à modéliser tout type de phénomène, il reste peu conseillé lorsque l’on dispose d’un nombre
Hypothèse préliminaire: 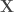
La forme générale du modèle GAM est la suivante :
![E[Y | X ^1, \dots, X ^P] = \alpha + \sum_{p = 1} ^P f_p (X ^p) + \sum_{k = 1} ^K f_k (X ^{p_1}, \cdots)](https://s0.wp.com/latex.php?latex=E%5BY+%7C+X+%5E1%2C+%5Cdots%2C+X+%5EP%5D+%3D+%5Calpha+%2B+%5Csum_%7Bp+%3D+1%7D+%5EP+f_p+%28X+%5Ep%29+%2B+%5Csum_%7Bk+%3D+1%7D+%5EK+f_k+%28X+%5E%7Bp_1%7D%2C+%5Ccdots%29&bg=ffffff&fg=404040&s=0&c=20201002)
Avec 
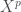
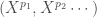
L’Algorithme Back-fitting
Il s’agit de la méthode de calcul des coefficients de régression la plus couramment utilisée. L’algorithme Back-fitting, introduit par Jerome Harold Friedman et Werner Stuelzle en 1981, est une procédure itérative qui ajuste séquentiellement chaque composante lissée en maintenant les autres. Cette approche est similaire à l’algorithme de rétropropagation généralisée.
– Etape d’initialisation : poser ![f_0 = E[Y] = \frac{1}{n} \sum_{i = 1} ^n Y_i](https://s0.wp.com/latex.php?latex=f_0+%3D+E%5BY%5D+%3D+%5Cfrac%7B1%7D%7Bn%7D+%5Csum_%7Bi+%3D+1%7D+%5En+Y_i&bg=ffffff&fg=404040&s=0&c=20201002)
![f_p ^0 = 0, \forall p \in[1, P]](https://s0.wp.com/latex.php?latex=f_p+%5E0+%3D+0%2C+%5Cforall+p+%5Cin%5B1%2C+P%5D&bg=ffffff&fg=404040&s=0&c=20201002)
– Etape itérative 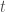
![p \in [1,P]](https://s0.wp.com/latex.php?latex=p+%5Cin+%5B1%2CP%5D&bg=ffffff&fg=404040&s=0&c=20201002)
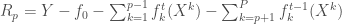
![f_p ^t = E[R_p | X ^p]](https://s0.wp.com/latex.php?latex=f_p+%5Et+%3D+E%5BR_p+%7C+X+%5Ep%5D&bg=ffffff&fg=404040&s=0&c=20201002)
Tant que,
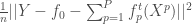
A noter que pour 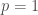
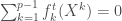
Et pour 
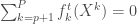
Enfin, l’estimation des différentes fonctions de lissage à l’instant 
Les transformations
Le modèle GAM se base donc sur la transformation de variables ou de combinaisons de variables afin bâtir son modèle prédictif. Elles portent le nom de fonctions de lissage et partagent toutes un concept bien particulier : celui d’ajustement par intervalle de valeurs appelé également « Nœud ». L’idée est d’optimiser le lissage partie par partie sans que les valeurs hors intervalles n’aient d’influence sur la zone focalisée. On peut définir ces nœuds soit arbitrairement soit en prenant les quantiles de distribution si l’on veut créer des intervalles de même longueur. Dans tous les cas on fixe le découpage suivant pour un nombre 
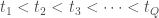
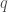
On aura à chaque fois autant de composantes de lissage, ou spline, que l’on fixera de nœuds. Une fois fait, on choisit parmi les principales fonctions de lissage suivantes pour la modélisation :
– La fonction Cubic Smoothing Spline de pénalité de courbure 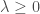
![CSS_q(X) = \sum_{i = 1} ^n [Y_i - g_q (X_i)] ^2 + \lambda \int_{[t_q, t_{q+1}]} (g_q '' (x)) ^2 dx](https://s0.wp.com/latex.php?latex=CSS_q%28X%29+%3D+%5Csum_%7Bi+%3D+1%7D+%5En+%5BY_i+-+g_q+%28X_i%29%5D+%5E2+%2B+%5Clambda+%5Cint_%7B%5Bt_q%2C+t_%7Bq%2B1%7D%5D%7D+%28g_q+%27%27+%28x%29%29+%5E2+dx&bg=ffffff&fg=404040&s=0&c=20201002)
, avec 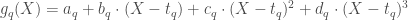
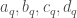
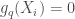
![X_i \not in ]t_q, t_{q+1}[](https://s0.wp.com/latex.php?latex=X_i+%5Cnot+in+%5Dt_q%2C+t_%7Bq%2B1%7D%5B&bg=ffffff&fg=404040&s=0&c=20201002)
– La fonction B-Splines à 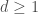
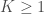
![\forall k \in [1, K], B_{k,d} (X) = \frac{(X - t_k)}{(t_{k + d} - t_{k})} \cdot B_{k, d-1} (X) + \frac{t_{k+d+1} - X}{t_{k+d+1} - t_{k+1}} \cdot B_{k+1,d-1} (X)](https://s0.wp.com/latex.php?latex=%5Cforall+k+%5Cin+%5B1%2C+K%5D%2C+B_%7Bk%2Cd%7D+%28X%29+%3D+%5Cfrac%7B%28X+-+t_k%29%7D%7B%28t_%7Bk+%2B+d%7D+-+t_%7Bk%7D%29%7D+%5Ccdot+B_%7Bk%2C+d-1%7D+%28X%29+%2B+%5Cfrac%7Bt_%7Bk%2Bd%2B1%7D+-+X%7D%7Bt_%7Bk%2Bd%2B1%7D+-+t_%7Bk%2B1%7D%7D+%5Ccdot+B_%7Bk%2B1%2Cd-1%7D+%28X%29&bg=ffffff&fg=404040&s=0&c=20201002)
, avec 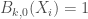
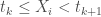
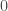
– La fonction Thin-Plate Smooting Spline :

, avec 
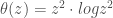
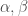
– La fonction P-Splines de force de pénalité
![f(x) = \sum_{k=1} ^K \beta_k \cdot B_{k,d} (X) + \lambda \int [f''(X)]^2 dx](https://s0.wp.com/latex.php?latex=f%28x%29+%3D+%5Csum_%7Bk%3D1%7D+%5EK+%5Cbeta_k+%5Ccdot+B_%7Bk%2Cd%7D+%28X%29+%2B+%5Clambda+%5Cint+%5Bf%27%27%28X%29%5D%5E2+dx&bg=ffffff&fg=404040&s=0&c=20201002)
, où 
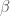
– La fonction LOESS de noyau 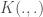
![LOESS(X) = min_{\alpha(x_0), \beta(x_0)} \sum_{i = 1} ^n K (x_0, X_i) \cdot [Y_i - \alpha(x_0) - \beta(x_0) \cdot X_i] ^2](https://s0.wp.com/latex.php?latex=LOESS%28X%29+%3D+min_%7B%5Calpha%28x_0%29%2C+%5Cbeta%28x_0%29%7D+%5Csum_%7Bi+%3D+1%7D+%5En+K+%28x_0%2C+X_i%29+%5Ccdot+%5BY_i+-+%5Calpha%28x_0%29+-+%5Cbeta%28x_0%29+%5Ccdot+X_i%5D+%5E2&bg=ffffff&fg=404040&s=0&c=20201002)
, où 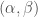
– La fonction de Base Radiale :
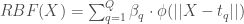
, où 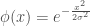
– La fonction Tensor Splines de 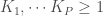
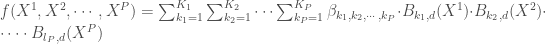
, où
Cette partie de l’article présente une esquisse de la démonstration des fonctions Cubic Smoothing Spline, LOESS et Thin-Plate Smooting Spline à estimer pour déterminer les valeurs de 
– On part de la formulation générique pour la fonction Cubic Smoothing Spline de paramètre 
![RSS(f,\lambda) = \sum_{i = 1} ^n [y_i - f(x_i)] ^2 + \lambda \int (f '' (t)) ^2 dt](https://s0.wp.com/latex.php?latex=RSS%28f%2C%5Clambda%29+%3D+%5Csum_%7Bi+%3D+1%7D+%5En+%5By_i+-+f%28x_i%29%5D+%5E2+%2B+%5Clambda+%5Cint+%28f+%27%27+%28t%29%29+%5E2+dt&bg=ffffff&fg=404040&s=0&c=20201002)
Lorsque 
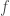


Pour obtenir une version simplifiée de la fonction Cubic Smoothing Spline, on pose 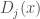
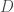
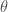
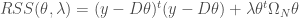
, avec 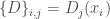
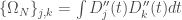

, qui s’apparente à la régression ridge généralisée. Après développement, on obtient ainsi la forme simplifiée de

– On part de la formulation générique pour la fonction LOESS de noyau 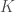
![min_{\alpha(x_0), \beta(x_0)} \sum_{i = 1} ^n K_{\lambda} (x_0,x_i) [y_i - \alpha(x_0) - \beta(x_0) x_i] ^2](https://s0.wp.com/latex.php?latex=min_%7B%5Calpha%28x_0%29%2C+%5Cbeta%28x_0%29%7D+%5Csum_%7Bi+%3D+1%7D+%5En+K_%7B%5Clambda%7D+%28x_0%2Cx_i%29+%5By_i+-+%5Calpha%28x_0%29+-+%5Cbeta%28x_0%29+x_i%5D+%5E2&bg=ffffff&fg=404040&s=0&c=20201002)
La fonction d’estimation est de la forme,
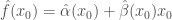
On définit alors la fonction du vecteur de valeurs 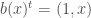
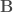

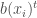
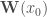
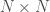
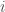
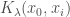
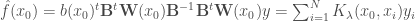
Ce qui donne une expression explicite pour l’estimation de la LOESS.
– On part de la formulation générique pour la fonction Thin-Plate Smooting Spline :

, avec 
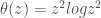
Soit 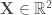
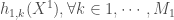
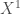

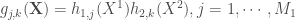
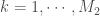
, que l’on peut généraliser avec la forme suivante,
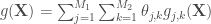
Pour estimer cette fonction, l’idée est de résoudre le problème suivant,
![min_J \sum_{i = 1} ^N \lbrace y_i - f(x_i) \rbrace ^2 + \lambda J[f]](https://s0.wp.com/latex.php?latex=min_J+%5Csum_%7Bi+%3D+1%7D+%5EN+%5Clbrace+y_i+-+f%28x_i%29+%5Crbrace+%5E2+%2B+%5Clambda+J%5Bf%5D&bg=ffffff&fg=404040&s=0&c=20201002)
, avec 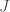
De plus, si le paramètre 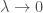
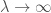
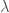
La solution est alors de la forme,
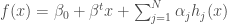
, où 
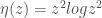
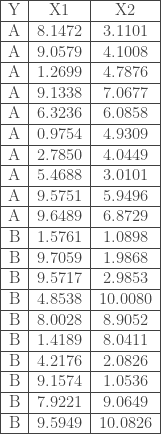
Soit l’échantillon 
Ci-dessous le nuage de points basé sur ces données,
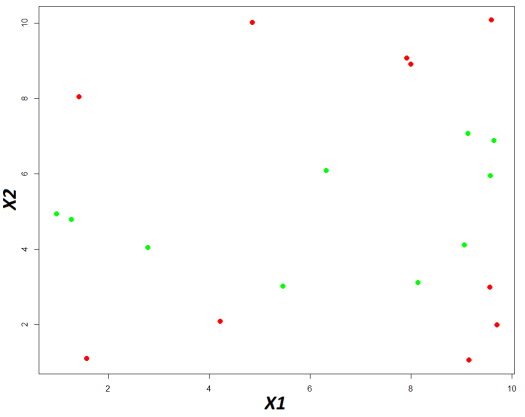
En vert la classe « A » et en rouge la classe « B »
On cherche donc à modéliser 
On applique sur 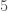
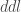

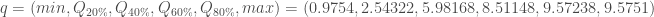
Pour chaque nœud, on calcule les valeurs de : 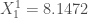
Pour la première composante :
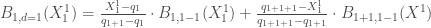
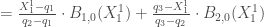
, or par définition 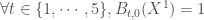
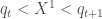
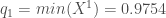
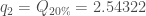
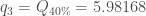
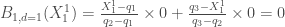
, puisque ![X_1 ^1 = 8.1472 \notin ]0.9754, 2.54322[](https://s0.wp.com/latex.php?latex=X_1+%5E1+%3D+8.1472+%5Cnotin+%5D0.9754%2C+2.54322%5B&bg=ffffff&fg=404040&s=0&c=20201002)
![\notin ]2.54322, 5.98168[](https://s0.wp.com/latex.php?latex=%5Cnotin+%5D2.54322%2C+5.98168%5B&bg=ffffff&fg=404040&s=0&c=20201002)
Ensuite, on calcul la seconde composante avec 
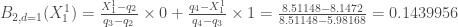
, puisque ![X_1 ^1 = 8.1472 \notin ]2.54322, 5.98168[](https://s0.wp.com/latex.php?latex=X_1+%5E1+%3D+8.1472+%5Cnotin+%5D2.54322%2C+5.98168%5B&bg=ffffff&fg=404040&s=0&c=20201002)
![\in ]5.98168, 8.51148[](https://s0.wp.com/latex.php?latex=%5Cin+%5D5.98168%2C+8.51148%5B&bg=ffffff&fg=404040&s=0&c=20201002)
Ensuite, on calcul la troisième composante avec 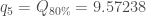
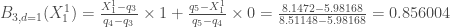
, puisque ![X_1 ^1 = 8.1472 \in ]5.98168, 8.51148[](https://s0.wp.com/latex.php?latex=X_1+%5E1+%3D+8.1472+%5Cin+%5D5.98168%2C+8.51148%5B&bg=ffffff&fg=404040&s=0&c=20201002)
![\notin ]8.51148, 9.57238[](https://s0.wp.com/latex.php?latex=%5Cnotin+%5D8.51148%2C+9.57238%5B&bg=ffffff&fg=404040&s=0&c=20201002)
Puis, on calcul la quatrième composante avec 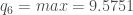

, puisque ![X_1 ^1 = 8.1472 \notin ]8.51148, 9.57238[](https://s0.wp.com/latex.php?latex=X_1+%5E1+%3D+8.1472+%5Cnotin+%5D8.51148%2C+9.57238%5B&bg=ffffff&fg=404040&s=0&c=20201002)
![\notin ]9.57238, 9.5751[](https://s0.wp.com/latex.php?latex=%5Cnotin+%5D9.57238%2C+9.5751%5B&bg=ffffff&fg=404040&s=0&c=20201002)
Et enfin, la cinquième composante :
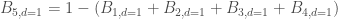
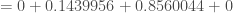

D’où,
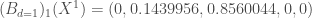
On généralise la méthode de calcul à tous les éléments de

On va maintenant appliquer la régression logistique de 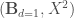

On pourra alors consulter cette article qui détaille l’algorithme de calcul : https://lemakistatheux.wordpress.com/category/outils-danalyse-supervisee/la-regression-logistique/
On obtient les résultats qui suivent :

Les performances obtenues peuvent être décrites au travers de la matrice de confusion suivante :

, soit un taux de bonne classification globale de 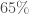

Les bandes rouges correspondent à la région de la classe « A » construite par le modèle, en bleu celle de la classe « B ». En rouge les données réelles de la classe « A » et en vert celles de la classe « B »
Soit l’exemple suivant :
E = data.frame(Y = c(rep(0,10),rep(1,10)),
X1 = c(8.1472, 9.0579, 1.2699, 9.1338, 6.3236, 0.9754, 2.7850, 5.4688, 9.5751, 9.6489, 1.5761, 9.7059, 9.5717, 4.8538, 8.0028, 1.4189, 4.2176, 9.1574, 7.9221, 9.5949),
X2 = c(3.1101, 4.1008, 4.7876, 7.0677, 6.0858, 4.9309, 4.0449, 3.0101, 5.9496, 6.8729, 1.0898, 1.9868, 2.9853, 10.0080, 8.9052, 8.0411, 2.0826, 1.0536, 9.0649, 10.0826))
Package et fonction R: https://stat.ethz.ch/R-manual/R-devel/library/mgcv/html/gam.html
La fonction gam du package mgcv permet de réaliser des modèles additifs généralisés. Après chargement du package, on lance la construction du modèle de la manière suivante :
model = gam(Y ~ bs(X1, df = 5, degree = 1) + X2, data = E, family = binomial(link = « logit »))
summary(model)
Parmi les éléments à insérer les plus importants il faut relever :
– La formule définissant variable réponse (à gauche) et variables explicatives (à droite) : 
– La base de données sur laquelle on souhaite travailler : 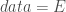
– La fonction lien : 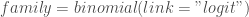
– La production de tous les détails du modèle construit : 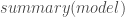
On obtient alors les résultats suivants :

On vérifie :
– La fonction lien : « Family : binomial », « Link function: logit » ;
– Le modèle paramétré : « Y ~ bs(X1, df = 5, degree = 1) + X2 » ;
– Les coefficients associés aux dérivations de
– Le niveau de significativité de chaque coefficient dans la dernière colonne : « Pr(>|Z|) » ;
– Et les performances du modèle sur les deux dernières lignes.
Soit l’exemple suivant :
data E;
input x1 x2 Y $1.;
cards;
8.1472 3.1101 A
9.0579 4.1008 A
1.2699 4.7876 A
9.1338 7.0677 A
6.3236 6.0858 A
0.9754 4.9309 A
2.7850 4.0449 A
5.4688 3.0101 A
9.5751 5.9495 A
9.6489 6.8729 A
1.5761 1.0898 B
9.7059 1.9868 B
9.5717 2.9853 B
4.8538 10.0080 B
8.0028 8.9052 B
1.4189 8.0411 B
4.2176 2.0826 B
9.1574 1.0536 B
7.9221 9.0649 B
9.5949 10.0826 B
;
run;
Procédure SAS: https://support.sas.com/documentation/cdl/en/statug/63033/HTML/default/viewer.htm#statug_gam_sect004.htm
La procédure GAM permet de réaliser des modèles additifs généralisés, toutefois elle n’offre pas un choix aussi varié que sous R. On lance la construction du modèle de la manière suivante :
proc gam data = E;
model Y (event = « B ») = spline(X1,df = 5) param(X2) / link = binomial;
ods exclude ConvergenceStatus InputSummary IterSummary ResponseProfile;
run;
Parmi les éléments à insérer les plus importants il faut relever :
– La base de données sur laquelle on souhaite travailler :
– La formule définissant variable réponse (à gauche) et variables explicatives (à droite) : 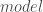
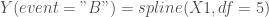
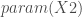
– La fonction lien : 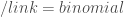
– L’ODS output est utilisé afin de ne filtrer que les résultats d’intérêt.
On obtient alors les résultats suivants :

On vérifie :
– Dans le premier tableau, la liste des coefficients associés à chaque variable brute du modèle
– Dans le deuxième tableau, le coefficient associé à la transformation de
– Dans le troisième tableau, les indicateurs de performance de la version transformée de
– The Elements of Statistical Learning de Trevor Hastie, Robert Tibshirani et Jerome Friedman ;
– Data Mining et statistique décisionnelle. L’Intelligence des données de Stéphane Tufféry.
