

Yoav Freund (à gauche) et Robert Shapire (à droite)

- Présentation
- Le Boosting
- Le concept général
- L’algorithme AdaBoost
- L’algorithme MARS
- Annexe théorique
- Exemple
- Application sous R
- Application sous SAS
- Bibliographie
Le Boosting est une famille d’outils d’analyse discriminante très puissants. L’idée est d’améliorer la règle de discrimination d’un classifieur sur plusieurs sous-parties de l’hyperplan formé par 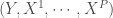
Le classifieur utilisé est la plupart du temps la régression linéaire, logistique ou les arbres de décision. Ils portent le nom de « classifieurs fiables » à la fois car ils sont simples d’utilisation mais également car l’objectif du Boosting est d’améliorer la règle de discrimination lorsqu’elle est peu performante.
Le Boosting appartient à la catégorie des méthodes d’apprentissage statistique nécessitant un jeu de d’apprentissage pour la conception de la règle d’apprentissage et un jeu de test pour sa validation afin de limiter les risques de sur-apprentissage. Comme la plupart d’entre elles, il a le principal défaut de concevoir une règle décisionnelle peu lisible d’où son surnom de boîte noire.
Parmi les méthodes de Boosting, la plus célèbre reste l’algorithme AdaBoost conçu par Yoav Freun et Robert Shapire en 1997 et définit pour la discrimination d’une variable réponse 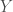
Hypothèse préliminaire: 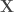
Le concept général
Avant d’aborder les algorithmes Adaboost et MART, on présentera l’algorithme de Boosting de base.
– Étape initiale : Définir un classifieur faible 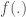
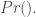

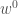
– Étapes itératives : Pour 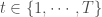
- Étape 1 : On apprend le modèle, selon apprentissage statistique via tirage pondéré par les
.
- Étape 2 : On applique le modèle construit, sur le sous-échantillon des observations qui n’ont pas été tirées à la première étape, aussi les
. Point important, si l’on ne souhaite pas utiliser d’apprentissage statistique alors ces deux premières étapes sont réalisées en même temps, on lance le classifieur faible directement en prenant en compte les
- Étape 3 : On mesure le taux d’erreurs de classification de la règle décisionnelle conçue précédemment par la fonction de coût :
.
- Étape 4 : On met à jour les pondérations
.
– Étape finale : On détermine la règle décisionnelle finale par vote sur
![\hat{Y}_t, \forall t \in [1,T]](https://s0.wp.com/latex.php?latex=%5Chat%7BY%7D_t%2C+%5Cforall+t+%5Cin+%5B1%2CT%5D&bg=ffffff&fg=404040&s=0&c=20201002)
L’algorithme AdaBoost
Pensé pour le cas où
– Étape initiale : Initialisation des pondérations associées aux observations,
![w_i ^0 = \frac{1}{n}, \forall i \in [1,n]](https://s0.wp.com/latex.php?latex=w_i+%5E0+%3D+%5Cfrac%7B1%7D%7Bn%7D%2C+%5Cforall+i+%5Cin+%5B1%2Cn%5D&bg=ffffff&fg=404040&s=0&c=20201002)
– Étapes itératives :
![\forall t \in [1,T]](https://s0.wp.com/latex.php?latex=%5Cforall+t+%5Cin+%5B1%2CT%5D&bg=ffffff&fg=404040&s=0&c=20201002)
- Étape 1-2 : Détermination, selon apprentissage statistique, des prédictions
en prenant en compte les poids
- Étape 3 : Calcul du taux d’erreurs :
;
- Étape 4 : Si
alors le classifieur fait mieux qu’une règle aléatoire et on conserve le modèle, sinon on ajuste,
- Le coefficient de pondération selon ses deux variantes :
La méthode de Breiman,
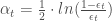
La méthode de Zhu pour le cas binaire,
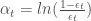
-
- Les pondérations :
![w_i ^t = w_i ^{t - 1} e ^{\alpha_t \cdot I_{(\hat{Y}_i \neq Y_i)}}, \forall i \in [1,n]](https://s0.wp.com/latex.php?latex=w_i+%5Et+%3D+w_i+%5E%7Bt+-+1%7D+e+%5E%7B%5Calpha_t+%5Ccdot+I_%7B%28%5Chat%7BY%7D_i+%5Cneq+Y_i%29%7D%7D%2C+%5Cforall+i+%5Cin+%5B1%2Cn%5D&bg=ffffff&fg=404040&s=0&c=20201002)
– Étape finale : On obtient le modèle final,
![H(x) = sign[\sum_{t = 1} ^T \alpha_t f_t (x)]](https://s0.wp.com/latex.php?latex=H%28x%29+%3D+sign%5B%5Csum_%7Bt+%3D+1%7D+%5ET+%5Calpha_t+f_t+%28x%29%5D&bg=ffffff&fg=404040&s=0&c=20201002)
L’Algorithme MART
L’Algorithme Multiple Additive Regression Trees se base sur l’utilisation d’arbres de régression. Par conséquent, il est adapté au cas où
– Étape initiale : Initialiser 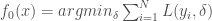
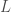
– Étapes itératives : Pour ![t \in [1, T]](https://s0.wp.com/latex.php?latex=t+%5Cin+%5B1%2C+T%5D&bg=ffffff&fg=404040&s=0&c=20201002)
- Étape 1 : Pour
calculer,
![r_{i,t} = - [\frac{\partial L(y_i, f(x_i))}{\partial f(x_i)}]_{f = f_{t - 1}}](https://s0.wp.com/latex.php?latex=r_%7Bi%2Ct%7D+%3D+-+%5B%5Cfrac%7B%5Cpartial+L%28y_i%2C+f%28x_i%29%29%7D%7B%5Cpartial+f%28x_i%29%7D%5D_%7Bf+%3D+f_%7Bt+-+1%7D%7D&bg=ffffff&fg=404040&s=0&c=20201002)
- Étape 2 : Estimer le modèle par arbre de régression sur
et donnant les régions décisionnelles
- Étape 3 : Pour
, calculer,
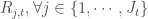
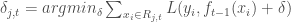
- Étape 4 : Mettre à jour
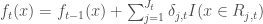
– Étape 2 : On a enfin la règle décisionnelle finale de forme
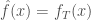
Cette partie de l’article présente une esquisse de la justification de l’usage de la fonction de perte exponentielle.
L’algorithme AdaBoost se base sur l’idée nouvelle d’une fonction de perte exponentielle dont le principal avantage est computationnel. En partant du principe que 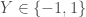
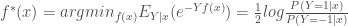
Et équivalent à,
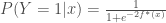
De cette manière, l’expansion additive produite par l’algorithme AdaBoost revient à estimer une partie du log-odds de 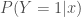
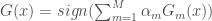
Un autre critère de minimisation de perte est la log-vraisemblance de la loi binomiale négative (appelée également déviance ou entropie croisée), interprétant 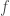
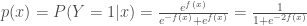
, avec 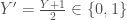
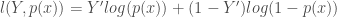
Et de déviance,

De la formule précédente, on voit que,
![E_{Y|x} [-l(Y,f(x))] = E_{Y|x} [e ^{-Y f(x)}]](https://s0.wp.com/latex.php?latex=E_%7BY%7Cx%7D+%5B-l%28Y%2Cf%28x%29%29%5D+%3D+E_%7BY%7Cx%7D+%5Be+%5E%7B-Y+f%28x%29%7D%5D&bg=ffffff&fg=404040&s=0&c=20201002)
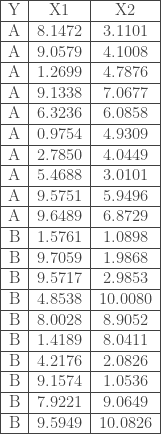
Soit l’échantillon 
Ci-dessous le nuage de point basé sur ces données,
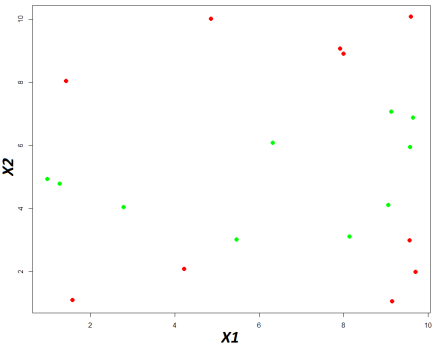
En vert la classe « A » et en rouge la classe « B »
On cherche donc à déterminer une fonction permettant de prédire les deux classes de 
On démarre en fixant les paramètres :
- Le classifieur faible sera l’arbre décisionnel, conformément au concept de l’AdaBoost, pour lequel on acceptera uniquement une profondeur d’un seul niveau ;
- L’échantillon complet servira de base d’apprentissage à chaque itération, comprendre que la règle produite le sera sur les
observations ;
- On utilisera la méthode de Breiman pour le calcul du taux d’erreur ;
- On initialise tous les poids à
pour chaque observation ;
- On choisit
itérations pour la convergence du modèle.
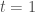 . On obtient le modèle suivant :
. On obtient le modèle suivant :
, et de performance de classification :

Soit un taux de mauvaise classification pondérée de :

, 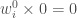
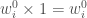
Comme on utilise la méthode de Breiman, alors l’erreur corrigée vaut :
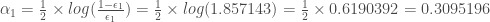
, que l’on propage ensuite pour rectifier le vecteur des pondérations

Enfin, on applique la dernière correction en divisant 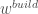
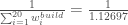
, d’où,

On vient de boucler la première itération. On lance maintenant la seconde 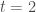
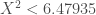
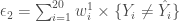

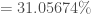
On calcule ensuite l’erreur corrigée :

, que l’on propage ensuite pour rectifier le vecteur des pondérations 

Enfin, on applique la dernière correction en divisant

, d’où :

On poursuit ainsi jusqu’à parcourir les 

, et le vecteur des erreurs corrigées :
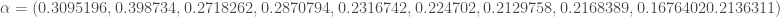
On procède au produit suivant afin de déterminer les scoring pour chaque observation :

En attribuant la classe finale en fonction de la valeur la plus importante on obtient les performances décrites au travers de la matrice de confusion suivante :

, soit un taux de bonne classification globale de 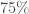
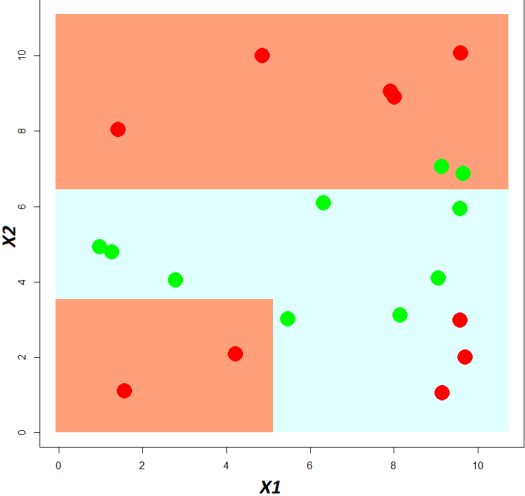
Les bandes rouges correspondent à la région de la classe « A » construite par le modèle, en bleu celle de la classe « B ». En rouge les données réelles de la classe « A » et en vert celles de la classe « B »
Soit l’exemple suivant :
E = data.frame(Y = c(rep(0,10),rep(1,10)),
X1 = c(8.1472, 9.0579, 1.2699, 9.1338, 6.3236, 0.9754, 2.7850, 5.4688, 9.5751, 9.6489, 1.5761, 9.7059, 9.5717, 4.8538, 8.0028, 1.4189, 4.2176, 9.1574, 7.9221, 9.5949),
X2 = c(3.1101, 4.1008, 4.7876, 7.0677, 6.0858, 4.9309, 4.0449, 3.0101, 5.9496, 6.8729, 1.0898, 1.9868, 2.9853, 10.0080, 8.9052, 8.0411, 2.0826, 1.0536, 9.0649, 10.0826))
Package et fonction R :
La fonction boosting du package adabag permet d’appliquer l’algorithme AdaBoost. Après chargement du package, on lance sa conception de la manière suivante :
boosting(Y ~ X1+X2, data = E, boos = FALSE, mfinal = 10, coeflearn = « Breiman », control = rpart.control(minsplit = 7,minbucket=7))
Parmi les éléments à insérer les plus importants il faut relever :
– La formule définissant variable réponse (à gauche) et variables explicatives (à droite) : 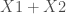
– La base de données sur laquelle on souhaite travailler : 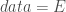
– La non utilisation d’un échantillonnage à chaque itération : 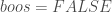
– Le nombre d’itérations total : 
– La correction de Breiman lors du calcul de l’erreur à chaque itération : 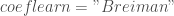
– Le paramétrage du classifieur faible qui sous R est obligatoirement l’arbre de décision : 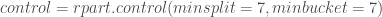
On obtient alors les résultats suivants :

On vérifie,
– Dans les sorties de type : ![\$trees[[.]]](https://s0.wp.com/latex.php?latex=%5C%24trees%5B%5B.%5D%5D&bg=ffffff&fg=404040&s=0&c=20201002)
– La somme des erreurs composants le vecteur 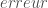
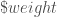
– La valeur finale des votes par observation : 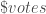

– Les classifications finales attribuées : 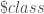
– Le poids d’influence des différentes variables du modèles : 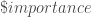
– Les autres sorties indiquent le paramétrage de la fonction.
Soit l’exemple suivant :
data BDD;
input x1 x2 Y;
cards;
8.1472 3.1101 A
9.0579 4.1008 A
1.2699 4.7876 A
9.1338 7.0677 A
6.3236 6.0858 A
0.9754 4.9309 A
2.7850 4.0449 A
5.4688 3.0101 A
9.5751 5.9495 A
9.6489 6.8729 A
1.5761 1.0898 B
9.7059 1.9868 B
9.5717 2.9853 B
4.8538 10.0080 B
8.0028 8.9052 B
1.4189 8.0411 B
4.2176 2.0826 B
9.1574 1.0536 B
7.9221 9.0649 B
9.5949 10.0826 B
;
run;
Il n’existe pas de procédure sous SAS permettant de lancer le Boosting. Par conséquent, on proposera la macro suivante :
On applique la macro de la manière suivante :
%Boosting(DATA = E, Y = Y, Classifieur = LOG, FctCout = Breiman, Iteration = 200);
Parmi les éléments à insérer, il faut relever :
– Le tableau sur lequel on veut travailler : 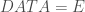
– Le nom de la réponse à discriminer : 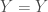
– Le type de classifieur même si un seul est disponible pour le moment (la régression logistique) : 
– La fonction coût même si une seule est disponible pour le moment (celle de Breiman) : 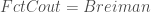
– Le nombre d’itérations à réaliser : 
On obtient alors les résultats suivants parmi les tableaux générés en fin de procédure :

, et :

Le premier tableau présente les pondérations finales : 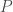
Le second tableau présente les classifications finales, étant donné que l’on a privilégié sous SAS un classifieur différent de celui utilisé pour les calculs manuels, les résultats ne pourront être comparés. On remarquera alors que si l’on avait utilisé une simple régression logistique, les performances sont de 
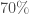
– The Elements of Statistical Learning de Trevor Hastie, Robert Tibshirani et Jerome Friedman ;
– The top ten algorithms in data mining de Xindong Wu et Vipin Kumar ;
– Probabilité, analyse des données et Statistique de Gilbert Saporta ;
– Data mining et statistique décisionnelle. L’intelligence des données de Stéphane Tufféry.
