

De gauche à droite : Daniel Bernoulli, Ronald Ross, William Ogilvy Kermack, Anderson Gray McKendrik et Richard Doll

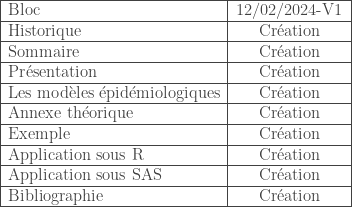
- Présentation
- Les modèles épidémiologiques
- Du modèle
au modèle
- Le compartiment
et le modèle
- Le modèle métapopulationnel
- Les effets naissances, migrations et décès naturels
- Quelques autres compartiments classiques
- Le nombre de reproduction effectif
- Du modèle
- Annexe théorique
- Les Equations Différentielles Ordinaires
- L’Algorithme d’Euler
- L’Algorithme de Runge-Kutta
- Exemple
- Le modèle
- Le modèle
métapopulationnel
- Le modèle
- Application sous R
- Application sous SAS
- Bibliographie
Les modèles compartimentaux épidémiologiques sont une famille d’outils d’anticipation et de compréhension des dynamiques de propagation des maladies, jouant un rôle central dans le domaine de la Santé publique. Ils ont fait énormément parler d’eux au cours de la crise Covid-19 mondiale traversée de 2020 à 2022. Leur principe consiste à s’appuyer sur une liste de paramétrages contextuels pour ensuite proposer une série de projections sur un nombre fixé de temps.
Les modèles épidémiologiques ont évolué au fil du temps grâce aux contributions de nombreux chercheurs, mathématiciens et épidémiologistes. Néanmoins, certaines figures clés ont marqué des étapes cruciales dans leur développement. On pourra citer Daniel Bernoulli qui, au XVIIIème siècle, a jeté les bases de la modélisation des phénomènes aléatoires, élément clé des modèles épidémiologiques. Bases qui ont été ensuite développées par Ronald Ross en contribuant à la modélisation mathématique des maladies infectieuses, notamment le paludisme, éclairant la compréhension de sa transmission par les vecteurs. Parmi les autres célébrités à évoquer, et cet article pêchera dans l’exhaustivité de cette liste, on peut également parler de William Ogilvy Kermack et d’Anderson Gray McKendrick qui, en 1927, publient un article fondateur introduisant le modèle 
Ces outils se basent sur la notion de système d’Equations Différentiels Ordinaires (EDO) et de leur résolution afin de déterminer à chaque itération les différents volumes associés aux compartiments considérés, permettant alors à tracer la courbe d’évolution de l’épidémie selon autant d’angles qu’il y a de compartiments.
Hypothèse préliminaire : Un jeu de paramètres en adéquation avec les différents compartiments utilisés.
– Du modèle
Il faut définir au préalable une unité de temps : 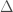


Il y a deux compartiments classiques dans les modèles épidémiologiques : le 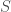
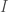
![\beta \in [0,1]](https://s0.wp.com/latex.php?latex=%5Cbeta+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=404040&s=0&c=20201002)
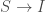
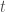

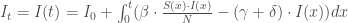
, à ce stade les paramètres 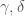
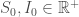

A noter que l’un des indicateurs phares utilisés pour le suivi des épidémies est celui du nombre ou incidence de nouveaux cas. On peut l’obtenir alors très facilement en l’extrayant de la formule, et de forme :

On enrichit le modèle en introduisant maintenant la notion de guérison grâce au compartiment 
![\gamma \in [0,1]](https://s0.wp.com/latex.php?latex=%5Cgamma+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=404040&s=0&c=20201002)

A noter que l’insertion de ce nouveau compartiment a également une incidence sur le compartiment 
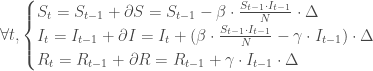
Enfin, on rajoute maintenant un dernier compartiment relatif aux décès : 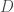
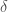
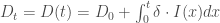
Tout comme pour le compartiment 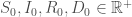

– Le compartiment
Le principal défaut que l’on peut trouver au modèle
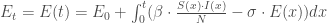

, en définissant le nouveau paramètre
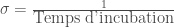
On fixe les états initiaux : 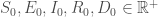

– Le modèle métapopulationnel
Une manière d’améliorer le modèle construit est d’intégrer dans son schéma d’Equations Différentielles l’information sur le taux de contact entre les différentes classes d’âge d’une population. Par exemple, si l’on suppose que l’épidémie que l’on cherche à modéliser se déroule dans un pays avec un moyenne d’âge particulièrement jeune, ajouter un paramètre qui permettra de pondérer le taux de transmission en fonction du taux de contact inter-classe d’âge pourra apporter un boost de précision très intéressant.
On doit donc définir ce l’on appelle une matrice de contacts de forme symétrique suivante :

, avec 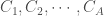
![\forall a_1, a_2 \in \lbrace 1, \cdots, C_A \rbrace, c_{a_1, a_2} \in [0,1]](https://s0.wp.com/latex.php?latex=%5Cforall+a_1%2C+a_2+%5Cin+%5Clbrace+1%2C+%5Ccdots%2C+C_A+%5Crbrace%2C+c_%7Ba_1%2C+a_2%7D+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=404040&s=0&c=20201002)
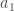
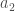
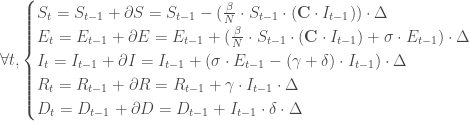
, avec 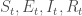


– Les effets naissances, migrations et décès naturels
Les modèles vus précédemment sont plus souvent utilisés pour les épidémies ponctuelles et sont d’ailleurs assez flexibles pour procéder à des réajustements lors d’une propagation en cours ou même établir des scénarios servant à modéliser plusieurs vagues successives. Pour cela il suffit simplement d’adapter les paramètres initiaux à la situation rencontrée. A partir du moment où l’objectif devient la modélisation d’un phénomène s’allongeant dans le temps, il est important d’intégrer dans son modèle les notions de :
- Nouvelles naissances, qui implique que la population croît régulièrement sur un profil bien spécifique venant ainsi alimenter uniquement le compartiment
;
- Effets migratoires, avec une perte ou un gain de population. Les notions de cas importés et autochtones prennent tout leur sens, et de fait, venant alimenter tous les compartiments. Cet effet sera noté
;
- Décès naturels, à ne pas confondre avec les décès du compartiment
.
Si l’on souhaite enrichir à nouveau le modèle

– Quelques autres compartiments classiques
Enfin, il est possible de rajouter pléthore de compartiments différents et variés dans l’objectif de coller au mieux au contexte :
- Le compartiment des vaccinés, noté
, intégrant à la fois le taux de vaccinés de départ et celui de nouveaux vaccinés ;
- Le compartiment des mis en quarantaine, noté
, intégrant le taux de mis en quarantaine, de guéris et de décès en quarantaine ;
- Le compartiment des asymptomatiques, noté
, intégrant le taux d’infectieux asymptomatiques qui présentent un enjeu important lors du contrôle d’une épidémie du fait qu’ils sont capables d’infecter d’autres porteurs sains et quasi-impossible à repérer ;
- Le compartiment des immunisés après infection et guérison, noté
, et son taux associé ;
- Le second compartiment
– Le nombre de reproduction de base
Le 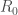
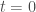
 ;
;
 ,
,  ;
;
 ,
, 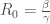 ;
;
 ,
, 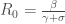 ;
;
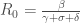 .
.Il est également possible de déterminer le nombre moyen de nouvelles infections à un instant 
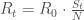
La différence essentielle entre
En termes de lecture, un 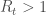
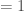
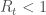
A noter que les formules du
– Les équations différentielles ordinaires
Les modèles épidémiologiques à compartiments se basent sur la notion de système d’Equations Différentielles Ordinaires (EDO). Pour obtenir une prévision à un instant 

, avec 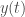
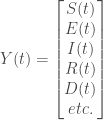
Les EDO disposent de plusieurs propriétés essentielles et offrant aux modèles épidémiologiques compartimentaux des caractéristiques des plus pratiques :
– Le théorème d’existence et d’unicité de Picard-Lindelöf et de Cauchy-Lipschitz permet aux EDO, sous certaines conditions, d’admettre une solution qui existe et est unique, relativement aux conditions initiales données ;
Théorème : Soit 
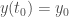
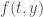

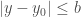
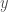
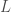


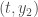




– De ce théorème découle également le concept d’EDO autonome, assurant son indépendance en fonction du temps. Cela signifie que les taux de variation des variables dépendent uniquement des valeurs actuelles des variables, et non du temps ;
– Le critère de stabilité de Nyquist et le critère de Hurwitz assure la stabilité linéaire pour les systèmes dynamiques décrits par des EDO. Pour les solutions non linéaires, c’est le théorème de stabilité de Lyapunov qui joue un rôle fondamentale. La notion de stabilité indique comment les solutions réagissent aux petites perturbations des conditions initiales ;
Définition : Soit un système dynamique décrit par l’équation différentielle
avec
variable de Laplace.
- Elle admet des valeurs spécifiques de
,
unité imaginaire et
fréquence angulaire.
- Après tracé de la fonction
, on peut conclure en la stabilité du système si et seulement si la courbe ne contourne pas le point critique
.
Définition : Soit un système dynamique décrit par l’équation différentielle
- L’équation :
.
- On détermine la matrice de Hurwitz associée aux coefficients de cette équation.
- On peut conclure en la stabilité du système si et seulement tous les mineurs principaux, ou déterminants associés aux sous-matrices, sont strictement positifs.
Définition : Soit 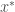
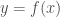



Supposons qu’il existe une fonction continue 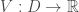
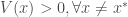
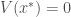

Alors, l’équilibre 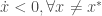
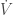
Ces caractéristiques des EDO font qu’elles sont couramment utilisées pour modéliser les systèmes dynamiques. Ces systèmes peuvent représenter divers phénomènes, tels que la croissance de la population, les mouvements planétaires, les réactions chimiques, etc. On peut les résoudre selon deux principales méthodes : l’algorithme de Newton et l’algorithme de Runge-Kutta.
– L’Algorithme d’Euler
L’algorithme d’Euler est une méthode itérative numérique, proposée par Leonhard Euler au XVIIIème siècle, utilisée pour résoudre des équations différentielles ordinaires. Dans le contexte des modèles épidémiologiques, cette méthode peut être appliquée pour résoudre des systèmes d’équations différentielles non linéaires, généralement associés à des modèles plus complexes. C’est une méthode itérative qui se base sur le principe que, près d’une solution, une fonction peut être approximée par une droite tangente à la courbe. Les itérations successives conduisent à une convergence rapide vers la solution.
Étapes de l’algorithme,
- Initialisation : Définir une équation différentielle
- Itérations :
;
- Avec
,
une estimation de
, et
est la dérivée de
.
- Répéter l’étape deux jusqu’à atteindre la fin de l’intervalle temporel spécifié.
– L’Algorithme de Runge-Kutta
L’algorithme de Runge-Kutta, développé par les mathématiciens allemands Carl Runge et Martin Kutta au début du XXe siècle, constitue une avancée significative dans la résolution numérique d’EDO. Leur objectif était d’améliorer la méthode d’Euler, en proposant une approche plus précise et stable pour approximer les solutions d’EDO. Les méthodes numériques Runge-Kutta, notamment celle d’ordre 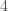

Étapes de l’algorithme,
- Initialisation : Définir une équation différentielle
- Itération :
- Calculer les coefficients intermédiaires
, et
comme suit,
;
;
;
.
- Mettre à jour la solution
;
- Mettre à jour le temps :
;
- Calculer les coefficients intermédiaires
- Répéter l’étape deux jusqu’à atteindre la fin de l’intervalle temporel spécifié.
Le modèle
On cherche à modéliser la propagation d’une maladie 
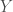
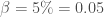
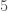

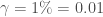
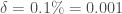
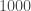

Enfin, on initialise la modélisation avec 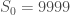
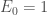
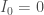
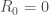
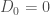
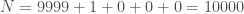
Ainsi, pour 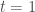
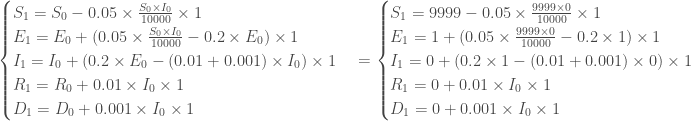
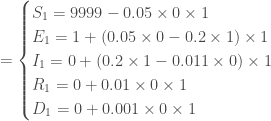
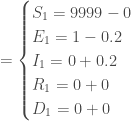
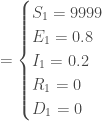
, avec à ce temps, un nombre de nouveaux cas de :
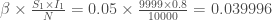
Pour 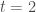
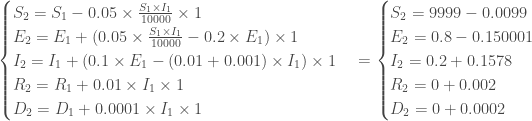
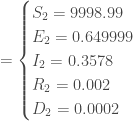
, avec à ce temps, un nombre de nouveaux cas de :
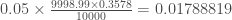
Pour 

, avec à ce temps, un nombre de nouveaux cas de :

On continue les calculs jusqu’à avoir parcouru tous les temps 

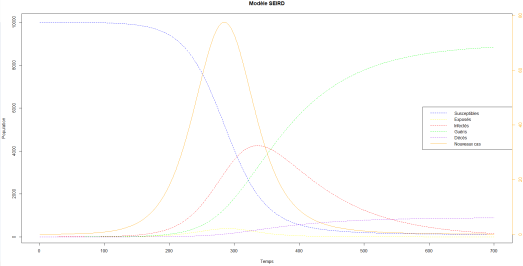
A la fin de cette vague, on extrait les indicateurs de Santé publique associés à l’épidémie de la maladie
– 

– 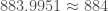

– Le pic de l’épidémie a eu lieu à 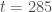
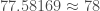
Le modèle
On cherche à modéliser la propagation d’une maladie
On inclut également la matrice de contacts entre les différentes classes d’âge que l’on a à disposition. Ces classes d’âge sont construites selon un découpage en cinq intervalles de même longueur :

Enfin, on initialise la modélisation avec 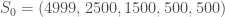
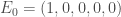
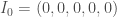
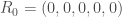

Soit un effectif total,

Ainsi, pour

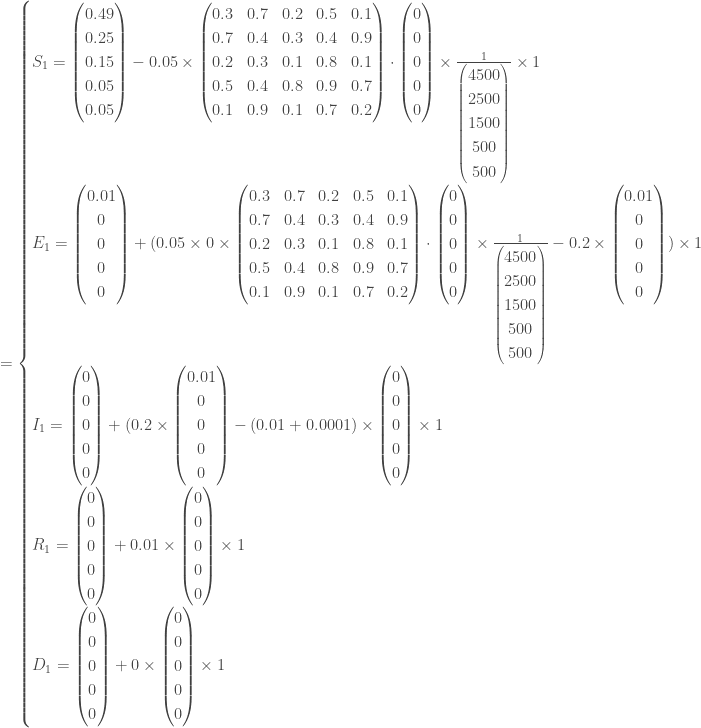
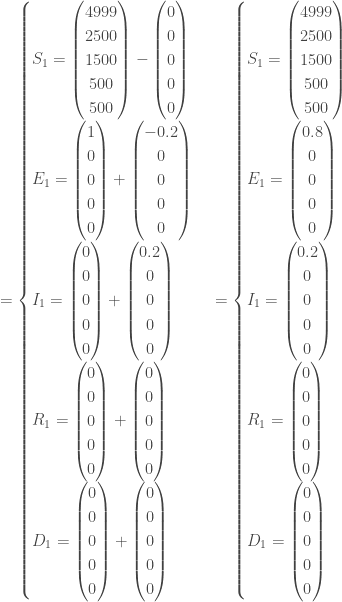
, avec à ce temps, un nombre de nouveaux cas par classe d’âge de :

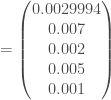
Pour

, avec à ce temps, un nombre de nouveaux cas par classe d’âge de :

Pour

, avec à ce temps, un nombre de nouveaux cas par classe d’âge de :

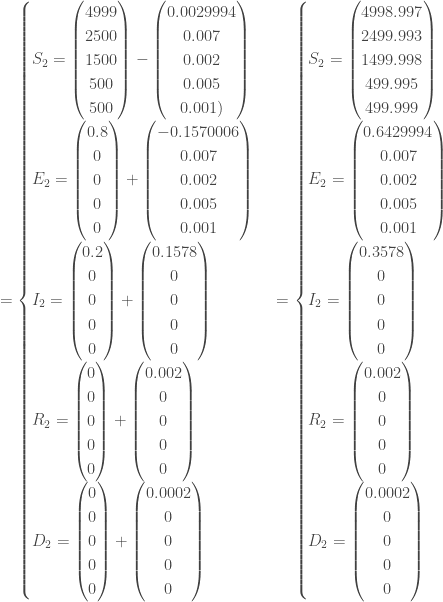
On continue les calculs jusqu’à avoir parcouru tous les temps

A la fin de cette vague, on extrait les indicateurs de Santé publique associés à l’épidémie de la maladie
– 

– 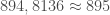
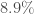
– Le pic de l’épidémie a eu lieu à 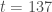
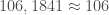
[latex]\bullet[/latex] Application sous R :
On proposera la fonction suivante permettant de produire des modélisations incluant les compartiments 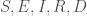
Model_epidemiologique = function(S0,E0,I0,R0,D0,beta,sigma,gamma,delta,pas,T) {
# La fonction s’adapte en fonction du paramétrage rentré. S0 correspond au volume d’individus susceptibles/sains de départ associé à beta le taux de contamination (si <= 0 alors le fonction ne se lance pas), E0 à celui d’exposés/contaminés n’ayant pas encore développé les symptômes associé à sigma le taux d’incubation (si <= 0 alors le compartiment est exclu), I0 à celui d’infectés, R0 à celui des guéris associé à gamma le temps de guérison (si <= 0 alors le compartiment est exclu) et D0 à celui des décédés suite à la pathologie étudiée associé à delta le taux de mortalité lié à la pathologie (si <= 0 alors le compartiment est exclu). Les paramètres pas et T représentant respectivement l’unité de temps et le nombre de temps total parcouru.
Model_epidemiologique = function(S0,E0,I0,R0,D0,beta,sigma,gamma,delta,pas,T) {
# Si l’on ne veut pas utiliser le compartiment E, et comme l’erreur est facile, on applique un réajustement ici si on s’est trompé
if (sigma == 0 && I0 == 0 && E0 > 0) {
print(« Attention, le paramètre sigma étant nul, le compartiment E ne sera pas utilisé, or sur votre paramétrage Sigma = 0, E > 0 et I = 0, aussi le programme va intervertir les valeurs de E et I »)
I0 = E0
E0 = 0
}
# Chargement de la bibliothèque pour la résolution d’équations différentielles
library(deSolve)
# Fonction générique du modèle SEIRD avec tous les compartiments voulus pour cette fonction
seird_model <- function(t, y, parameters) {
with(as.list(c(y, parameters)), {
dS = (-beta * S * I / N) * pas
if (sigma > 0) {
dE = (beta * S * I / N – sigma * E) * pas
dI = (sigma * E – (gamma + delta) * I) * pas
}
if (sigma == 0) {
dE = 0
dI = (beta * S * I/N – gamma * I) * pas
}
dR = (gamma * I) * pas
dD = (delta * I) * pas
return(list(c(dS, dE, dI, dR, dD)))
})
}
# Conditions initiales
initial_conditions = c(S = S0, E = E0, I = I0, R = R0, D = D0)
# Création du vecteur des différents temps
times = seq(0, T, by = pas)
# Auto-configuration des paramètres du modèle pour l’utilisation de la fonction ode du package deSolve
NAME = « S »
CHOIX = « S »
initiale_state = 1
LEGEND = « Susceptibles »
COL = « blue »
parameters = c(beta = beta)
if (sigma > 0) {
NAME = paste(NAME, « E »)
CHOIX = c(CHOIX, »E »)
LEGEND = c(LEGEND, « Exposés »)
COL = c(COL, « yellow »)
parameters = c(parameters, sigma = sigma)
}
if (beta > 0) {
NAME = paste(NAME, « I »)
CHOIX = c(CHOIX, »I »)
LEGEND = c(LEGEND, « Infectés »)
COL = c(COL, « red »)
}
if (gamma > 0) {
NAME = paste(NAME, « R »)
CHOIX = c(CHOIX, »R »)
LEGEND = c(LEGEND, « Guéris »)
COL = c(COL, « green »)
parameters = c(parameters, gamma = gamma)
}
if (delta > 0) {
NAME = paste(NAME, « D »)
CHOIX = c(CHOIX, »D »)
LEGEND = c(LEGEND, « Décès »)
COL = c(COL, « purple »)
parameters = c(parameters, delta = delta)
}
# Calcul de la population totale pour application des équations différentielles
N = S0 + E0 + I0 + R0 + D0
parameters = c(parameters, pas = pas, N = N)
# Si le paramètre beta est différent de 0 alors on peut lancer la modélisation, si ce dernier est égal à 0, au regard de la formule des équations différentielles, assez logiquement on ne peut lancer les calculs
if (beta > 0) {
# Résolution des équations différentielles avec la fonction ode
result = ode(y = initial_conditions, times = times, func = seird_model, parms = parameters)
# Sélection des colonnes d’intérêt en fonction du type de modèle décrit par les paramètres entrés
result = result[,c(« time »,CHOIX)]
# Tracé des résultats
plot(times, result[, « S »], type = « l », lty = 1, col = « blue », xlab = « Jours », ylab = « Population », main = NAME, ylim = c(0,N))
for (p in 3:dim(result)[2]) {lines(times, result[, CHOIX[p-1]], lty = 1, col = COL[p – 1])}
legend(« topright », legend = LEGEND, col = COL, lty = 1)
}
if (beta == 0) {print(« A minima, le paramètre Beta doit être > 0 »)}
}
On souhaite lancer la modélisation d’un
Model_epidemiologique(S0=9999,E0=1,I0=0,R0=0,D0=0,beta=0.05,sigma=0.2,gamma=0.01,delta=0.001,pas=1,T=1000)
Parmi les éléments à insérer les plus importants il faut relever :
– Le volume de susceptibles de départ :
– Le volume d’exposés de départ :
– Le volume d’infectés de départ :
– Le volume de guéris de départ : 
– Le volume de décédés de départ :
– Le taux de contamination : 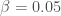
– Le taux d’incubation : 
– Le taux de guérison : 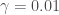
– Le taux de décès : 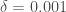
On obtient alors les résultats suivants :

, qui sont alors les mêmes que ceux obtenus lors des calculs manuels (cf partie « Exemple »).
On proposera la macro suivante permettant de produire des modélisations incluant les compartiments
On souhaite lancer la modélisation d’un
%Model_epidemiologique(S0=9999, E0=1, I0=0, R0=0, D0=0, beta=0.05, sigma=0.2, gamma=0.01, delta=0.001, pas=1, T=100);
Parmi les éléments à insérer les plus importants il faut relever :
– Le volume de susceptibles de départ :
– Le volume d’exposés de départ :
– Le volume d’infectés de départ :
– Le volume de guéris de départ :
– Le volume de décédés de départ :
– Le taux de contamination :
– Le taux d’incubation :
– Le taux de guérison :
– Le taux de décès :
On obtient alors les résultats suivants :

, qui sont alors les mêmes que ceux obtenus lors des calculs manuels (cf partie « Exemple »).
– A contribution to the mathematical theory of epidemics de W. O. Kermack et A. G. McKendrick ;
– Infectious diseases of humans : Dynamics and control de R. M. Anderson et R. M. May ;
– On the definition and the computation of the basic reproduction ratio R0 in models for infectious diseases in heterogeneous populations de O. Diekmann, J. A. Heesterbeek et J. A. Metz ;
– The mathematics of infectious diseases de H. W. Hethcote ;
– Modeling infectious diseases in humans and animals de M. J. .Keeling et P. Rohani ;
– Reproduction numbers and sub-threshold endemic equilibria for compartmental models of disease transmission de P. Van den Driessche et J. Watmough ;
– Appropriate models for the management of infectious diseasesde H. J. Wearing, P. Rohani et M. J. Keeling ;
– Le site web : https://images.math.cnrs.fr/Modelisation-d-une-epidemie-partie-1.html ;
– Simulation des Equations Différentielles Stochastiques sous R de A. C. Guidoum.
