

Warren McCulloch (à gauche) et Walter Pitts (à droite)

- Présentation
- Les réseaux de neurones
- Vocabulaire
- L’algorithme
- Autres particularités
- Les réseaux à base radiale
- Annexe théorique
- Exemple
- Application sous R
- Application sous SAS
- Bibliographie
Les réseaux de neurones ou neuronale, outil d’analyse supervisée qui prend ses racines dans les années 1940 et connait un essor constant de développement depuis, permet de discriminer une matrice de 
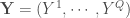
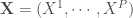
Les réseaux de neurones se sont construits une solide réputation au fil du temps, marquée par des hauts et des bas, dépendante de l’engouement mais aussi de la lassitude du moment. Relégués au statut de boîte noire, ils demeurent aussi riches que leur histoire. Initialement conceptualisés par Warren McCulloch et Walter Pitts en 1943, introduisant la notion de neurone formel, leur idée était de s’inspirer des neurones et des synapses du cerveau humain et de les mathématiser. Le concept a progressé, et en 1950, cette idée a pris forme avec la création du Perceptron par Frank Rosenblatt. Malheureusement, en 1969, Marvin Lee Minsky et Seymour Papert ont souligné d’importantes limites théoriques, entraînant une chute vertigineuse de l’enthousiasme généré, jusqu’au début des années 1980.
En 1982, John Joseph Hopfield introduit une version portant son propre nom et généralise la notion de base des neurones connectés de McCulloch et Pitts. Puis, en 1986, David Rumelhart, Geoffrey Hinton et Ronald J. Williams développent l’algorithme de rétropropagation du gradient pour l’apprentissage, faisant tomber un à un les détracteurs des réseaux de neurones. Cela ressuscite tout l’engouement qu’ils avaient généré autrefois et les propulse jusqu’à une utilisation courante en industrie à partir des années 1990. Leur essor reprend ainsi de plus belle et, dans les années 2000 avec l’augmentation exponentielle de la puissance de calcul des ordinateurs, valide l’arrivée des réseaux de neurones profonds (DNN), convolutionnels (CNN) et récurrents (RNN). Les désagréments théoriques balayés, les réseaux de neurones peuvent s’épanouir, permettant des avancées significatives dans le domaine du traitement du langage naturel. Depuis les années 2010, ils accumulent de nombreux succès remarquables dans divers domaines tels que le traitement de l’image, la traduction automatisée et la santé.
Malgré les éloges envers les réseaux de neurones, il faut rappeler qu’il s’agit d’un outil d’une haute complexité, manquant de lisibilité, capable de reproduire n’importe quelle fonction, notamment en raison de leur paramétrage et du risque accru de sur-apprentissage du phénomène que l’on cherche à modéliser ou encore de la convergence vers une solution globale et non locale. D’une certaine manière, ils sont déjà limités à une utilisation sur de grandes bases de données pour justement minimiser ce risque.
Enfin, bien que présentés ici comme un outil de classification et de prédiction, il existe également une version pour mener des analyses non supervisées, comme les cartes auto-organisatrices de Kohonen.
Hypothèse préliminaire : Tout format de variable 
Vocabulaire
Avant de se lancer dans une vision plus approfondie des réseaux de neurones, il est important de rappeler le vocabulaire associé.
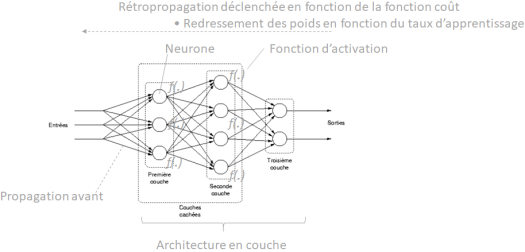
– Neurones, ou nœuds, et connexions synaptiques : unités de traitement, ou calculateur, interconnectées par des poids synaptiques. Chaque connexion synaptique a un poids qui détermine l’importance de la contribution d’un neurone à l’activation d’un autre ;
– Architecture ou topologie : structure du réseau distinguée généralement selon trois types. La couche d’entrée qui recevra les données initiales, les couches cachées qui effectueront les transformations intermédiaires, la couche de sortie qui retournera la modélisation finale. Dès lors où l’on aura plusieurs couches cachées on parlera de réseaux de neurones profonds ;
– Fonction d’activation ou de transfert : introduit la non-linéarité dans le réseau et ainsi la capacité de cet outil à modéliser des relations complexes. Cette dernière interviendra lors de la propagation avant alors que sa dérivée interviendra lors de la rétropropagation ;
– Propagation avant (feedforward) : les données circulent à travers le réseau de la couche d’entrée à la couche de sortie sans rétroaction. Chaque neurone transmet son activation aux neurones de la couche suivante. Il s’agit de la partie non supervisée de l’algorithme car ne faisant pas intervenir la réponse ;
– Rétropropagation (backpropagation) : ajustement des poids synaptiques du réseau en fonction de l’erreur calculée entre la sortie prédite et la sortie réelle. Son objectif est de minimiser cette erreur en temps réel, en ajustant les poids de manière itérative. il s’agit de la partie supervisée de l’algorithme ;
– Fonction de coût : mesure de l’écart entre la sortie prédite et la sortie réelle que la rétropropagation va chercher à chaque itération de minimiser ;
– Taux d’apprentissage : servant à déterminer la taille du pas que l’algorithme de rétropropagation prend pour ajuster les poids du réseau. Plus il est haut et plus la convergence est rapide au risque de s’arrêter sur une solution locale et non globale. Alors que plus il est faible, plus l’on devra utiliser d’itérations pour obtenir la convergence, favorisant ainsi les chances de trouver la solution globale.
Enfin, afin d’avoir une vision simple de toutes ces notions, on conclura avec la graphique suivant :
L’algorithme
On part d’une matrice 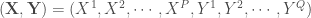
L’algorithme que l’on proposera n’intègre que les concepts de rétropropagation et d’apprentissage profond. Il s’approche plus particulièrement d’un type de réseau de neurones qui porte le nom de Perceptron multicouche. En voici les différentes étapes :
Etape 1 : Choix du paramétrage du réseau de neurones,
- On définit le nombre
de couches cachées. Pour chaque couche
, on désigne un nombre de neurones
. On a volontairement mis la paramétrage possible à
couche cachée afin de rappeler qu’il est possible, revenant à faire une simple régression linéaire ou logistique en fonction de la fonction d’activation choisie. Plus l’on ajoute de couches cachées et plus le pouvoir prédictif du modèle s’en voit amélioré, mais c’est aussi là que réside l’un des plus gros risques de surapprentissage. De nombreux auteurs proposent des méthodes différentes pour le choix du nombre de couches cachées. S. Tufféry, par exemple, indique qu’il faut compter
à
individus pour ajuster chaque poids et qu’il vaut mieux se concentrer sur l’utilisation au maximum de deux couches cachées puis jouer sur les autres paramètres pour améliorer son réseau de neurones.
- On définit la fonction d’activation. La plus communément utilisée est la fonction logistique ou sigmoïde
et de dérivée :
. Mais on en retrouve d’autres qui le sont également dans une moindre mesure,
– ReLU (Rectified Linear Unit) : 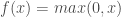
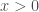
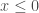
– Leaky ReLU (Unité Linéaire Paramétrique) : 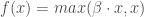
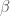
– Tangente hyperbolique : 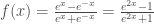
![[-1, 1]](https://s0.wp.com/latex.php?latex=%5B-1%2C+1%5D&bg=ffffff&fg=404040&s=0&c=20201002)
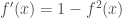
– ELU (Unité Linéaire Exponentielle) : 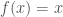
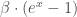
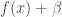
– Softmax : 
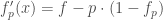
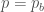


– Swish : 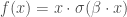

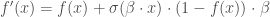
Le choix de la fonction d’activation se fait en lien avec la nécessité d’avoir une fonction linéaire au voisinage de ![[0, 1]](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D&bg=ffffff&fg=404040&s=0&c=20201002)
![[-1,1]](https://s0.wp.com/latex.php?latex=%5B-1%2C1%5D&bg=ffffff&fg=404040&s=0&c=20201002)
- On définit les poids (synaptiques) initiaux associés aux différentes couches. De préférence, aléatoirement. En effet, démarrer avec des poids identiques risque fortement d’entrainer la non-différenciation des neurones. Ce phénomène est connu sous le terme de « problème des neurones morts », diminuant leur capacité d’apprentissage. Xavier Glorot propose de délimiter le périmètre de tirage en divisant chacun des poids par :
. Pour chacune des couches cachées
, on notera
la matrice des poids de taille
si
,
si
. Enfin, il faut également attribuer à la couche de sortie ses propres pondérations
, tirées de la même manière et de taille
. A noter que l’ajout de
systématiquement est lié au besoin d’avoir, sans que cela soit obligatoire mais simplement conseillé, une ligne supplémentaire de poids associés aux termes constants.
- On définit le taux d’apprentissage
, qui servira à fixer la vitesse de correction des matrices de pondérations. Ce dernier étant un pourcentage, il doit être compris dans
- On définit un nombre d’itérations
à appliquer afin d’arrêter l’algorithme qu’il converge ou non.
Etape 2 : Propagation avant (apprentissage non supervisé), en notant 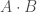
- Pour la première couche cachée :
;
- Dès la seconde couche cachée :
;
- Pour la couche de sortie :
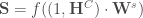
En fait, cette étape de l’algorithme remet un peu en question la vision traditionnelle du réseau de neurones que l’on veut à tout prix opposer à celle du cerveau, ce qui est normal puisqu’il s’agit du concept de base à l’origine de l’outil. Mais on comprend mieux certaines présentations qui consistent à le représenter comme une succession de « plaques » contre lesquels l’on va jeter notre jeu de données, l’éparpillant matriciellement pour à nouveau le rejeter comme une nouvelle plaque qui va l’éparpiller à son tour. Et ainsi de suite jusqu’à ce qu’à force d’exploser nos données, elles finissent par se remettre dans le bon ordre. On retrouve ici l’approche non supervisée puisque l’on n’utilise pas notre réponse
Enfin, à noter que cette partie de l’algorithme fait également aussi office de règle décisionnelle. Munis des poids et d’un nouvel individu décrit selon les caractéristiques utilisées pour le paramétrage, il suffit d’appliquer les itérations indiquées précédemment pour obtenir sa prédiction.
Etape 3 : Calcul de l’erreur, on compare la sortie prédite 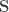
– L’erreur quadratique moyenne (MSE) : 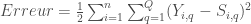
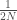

– L’entropie croisée binaire (Binary Cross-Entropy) : 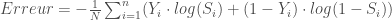
– L’entropie croisée catégorielle (Categorical Cross-Entropy) : 
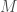
Etape 4 : Rétropropagation (apprentissage supervisé), l’erreur calculée est propagée en sens inverse à travers le réseau. Les poids synaptiques sont ajustés de manière itérative pour minimiser cette erreur. Cela se fait en utilisant la descente de gradient, où la dérivée partielle de la fonction de coût. en notant 
– On démarre sur la couche de sortie,
- Initialiser
, sachant que certains réseaux programmés font intervenir la dérivée de la fonction coût à la place de la formule proposée ;
- Calculer les corrections des poids de la couche de sortie
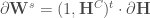
– Puis sur la dernière couche cachée,
- Mettre à jour la dérivation
, la matrice des poids de la couche de sortie est utilisée cette fois-ci en lui retirant la première ligne ;
- Calculer les corrections des poids de la dernière couche cachée en faisant intervenir la dérivée de la fonction d’activation
, et en notant
le produit terme à terme,

– Puis en poursuivant couche par couche en sens inverse, ![\forall c \in [C-1, \cdots, 2]](https://s0.wp.com/latex.php?latex=%5Cforall+c+%5Cin+%5BC-1%2C+%5Ccdots%2C+2%5D&bg=ffffff&fg=404040&s=0&c=20201002)
- Itérativement mettre à jour la dérivation
, la matrice des poids de la couche
est utilisée en lui ôtant la première ligne ;
- Calculer les corrections des poids de la couche
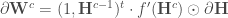
– Enfin, une fois arrivé à la première couche,
- On met à jour la dérivation
, la matrice des poids de la seconde couche est utilisée en lui supprimant la première ligne ;
- Calculer les corrections des poids de la première couche,
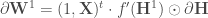
Etape 5 : On dispose désormais des matrices de correction des différentes couches 
![\forall c \in [1, \cdots, C, S], \mathbf{W} ^c \leftarrow \mathbf{W} ^c - \alpha \cdot \partial \mathbf{W} ^c](https://s0.wp.com/latex.php?latex=%5Cforall+c+%5Cin+%5B1%2C+%5Ccdots%2C+C%2C+S%5D%2C+%5Cmathbf%7BW%7D+%5Ec+%5Cleftarrow+%5Cmathbf%7BW%7D+%5Ec+-+%5Calpha+%5Ccdot+%5Cpartial+%5Cmathbf%7BW%7D+%5Ec&bg=ffffff&fg=404040&s=0&c=20201002)
L’algorithme de la descente du gradient, présenté ici, est le plus répandu mais demeure cependant sensible aux minimums locaux. Parmi les autres méthodes existantes : l’algorithme de Levenberg-Marquardt optimal pour les petits réseaux, quasi-Newton, gradient conjugué meilleur compromis pour les réseaux complexes, propagation rapide ou encore les algorithmes génétiques. Concernant celui présenté ici, on peut retrouver dans la littérature plusieurs amélioration comme l’optimisation stochastique, la régularisation (pour éviter le surapprentissage) et des techniques avancées telles que les algorithmes Adam, RMSprop, etc.
– Etape 6 : Sur le nombre d’itérations 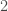
Enfin, et comme tout bon outil de type data mining, il convient de valider le modèle construit par précédés empiriques. On lance alors ces étapes sur un échantillon d’apprentissage obtenu soit en scindant l’échantillon de base (cross-validation, LOOCV, tirage aléatoire de deux tiers de l’échantillon) et de valider la modèle « tuné » obtenu sur un échantillon test. L’objectif étant d’obtenir les mêmes performances sur échantillon test et échantillon de validation. Si c’est le cas on peut le valider, sinon il faut en reconstruire un nouveau.
Autres particularités
Comme indiqué, l’algorithme présenté ici est assez incomplet vis à vis de ceux des véritables réseaux de neurones implémentés sur bon nombre de langage de programmation de nos jours. Parmi les nombreux concepts non évoqués précédemment on a :
– La convolution, donnant leur nom aux réseaux CNN, consiste à appliquer un filtre (ou noyau) directement sur
– La normalisation par lots (Batch Normalization) est un concept introduit pour résoudre les problèmes de convergence « lente », d’explosions du gradients et ainsi gagner en stabilité du modèle. Initialement développé pour les CNN, elle est désormais utilisée pour tout type de réseau. Il s’agit de composer un certain nombres de sous-échantillon des données d’origine, appelés mini-batch, et pour chaque sortie de neurone 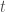
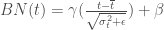
, avec 

Concrètement et si l’on reprenait l’algorithme décrit, cela reviendrait à appliquer la fonction d’activation après Batch Normalisation du produit scalaire pour la propagation. Et lors de la rétropropagation, appliquer le processus de calcul inversé sur 
Un mot sur le réseau résiduel (Residual Networks ou ResNets) dont le concept vise à introduire des sauts de connexion pour faciliter le flux d’information à travers le réseau, permettant l’entrainement de réseaux beaucoup plus profonds. Souvent couplé à la Batch Normalisation, il s’agit alors de l’appliquer sur certaines couches et pas systématiquement à toutes.
– Et encore de nombreux et autres nombreux concepts, tels que les fonctions d’erreur ou coût adaptatives, les méthodes de régularisation (régression Ridge, Lasso, Elasticnet, etc.), les méthodes des moments permettant de contrôler le risque que les pondérations partent dans un unique sens et aillent s’enterrer vers une solution locale, etc., que l’on ne définira pas ici. L’on invitera alors le lecteur à se fournir en ouvrage spécialisé sur le sujet tant il y en a pléthore.
Les réseaux à base radiale :
On dénombre énormément de type de réseaux différents, adaptés selon le format des données en entrée comme par exemple celles appariées ou temporelles. Une fois de plus, il est conseillé de s’orienter ensuite vers des ouvrages spécialisés. Toutefois, on pourra laisser un mot sur l’une des alternatives les plus connues au Perceptron Multicouche, les réseaux à base radiale (RBF).
Ils se distinguent par une architecture composée d’une couche d’entrée, d’une unique couche cachée utilisant des fonctions radiales comme la fonction gaussienne 

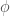
Les RBF présentent les avantages d’une capacité à apprendre à modéliser des relations non linéaires grâce aux fonctions radiales et sont moins sensibles au surajustement par rapport au Perceptron Multicouche. Quant aux inconvénients majeurs, ils nécessitent la sélection des centres et des paramètres radiaux parfois difficile ainsi que des performances potentiellement inférieures sur des tâches plus complexes comparées aux Perceptron Multicouche.
On présentera ici une esquisse de la démonstration de l’apport de l’algorithme de rétropropagation sur la qualité de modélisation des réseaux de neurones.
En notant
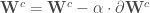
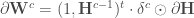
L’apport de la rétropropagation sur l’estimation des paramètres provient du terme 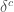
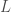
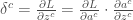
, avec,
– 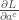
– 
Maintenant, pour le taux d’apprentissage
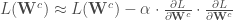
Si 
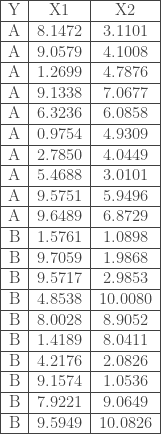
Soit l’échantillon 
Ci-dessous le nuage de point basé sur ces données,
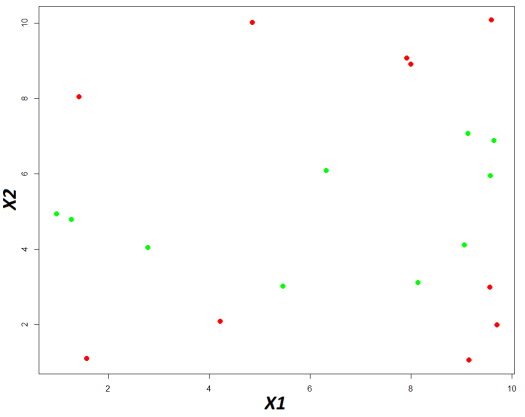
En vert la classe « A » et en rouge la classe « B »
On cherche donc à déterminer une fonction permettant de prédire les deux classes de 
On opte pour le paramétrage suivant :
– Une architecture formée d’une couche d’entrée à 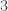
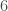
– La fonction d’activation choisie sera la fonction sigmoïde : 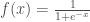
– La fonction coût : 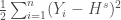
– Le taux d’apprentissage : 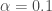
– Et pour les poids, on tire aléatoirement ceux associés à la première couche cachée de taille 
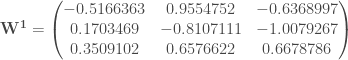
, à la seconde couche cachée de taille 

, et à la couche de sortie de taille 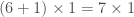
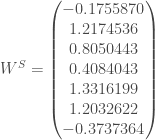
L’étape d’initialisation étant réglée, on passe à la suite avec l’utilisation de l’algorithme de propagation avant. Donc, pour l’itération N°
– La phase de propagation, en débutant par celle dans la première couche se calcul via :

On obtient alors,
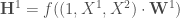
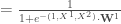
– Pour celle de la seconde couche :
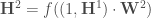

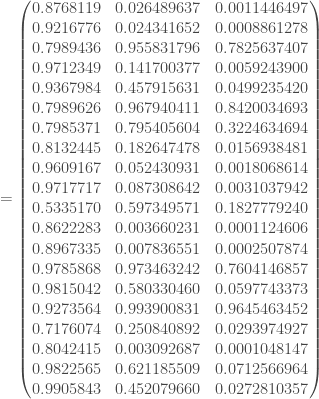
– Et enfin, la couche de sortie :
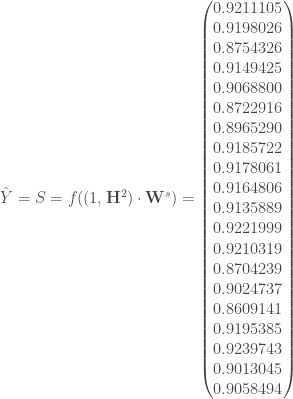
Avant de passer à l’étape de rétropropagation, on calcul le taux d’erreur global, en créant un vecteur numérique associé à la réponse
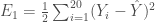
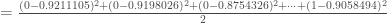
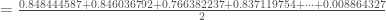
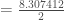
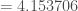
– La phase de rétropropagation. Avant, on va calculer et incrémenter le terme :

, et maintenant la matrice correctrice des poids associées à la couche de sortie :
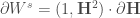


Avant de procéder à la rétropropagation sur la seconde couche cachée, on met à jour :
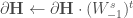


Et puis on travaille sur la seconde couche, en faisant intervenir la dérivée de la fonction d’activation, d’où l’utilisation du terme 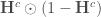
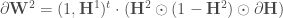


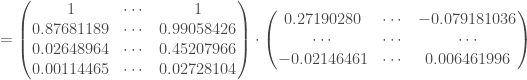

Avant de boucler la rétropropagation, on met à nouveau à jour :

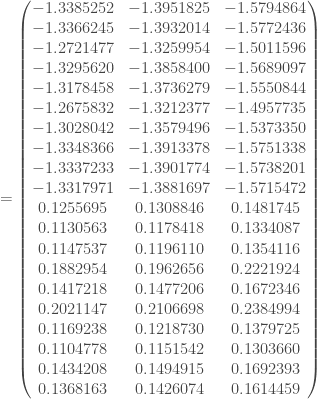
Et enfin, on travaille sur la première couche cachée, en faisant à nouveau intervenir la dérivée de la fonction d’activation :
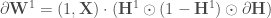
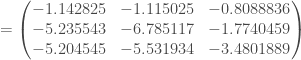
Les termes d’ajustement sont désormais tous déterminés, il ne reste plus qu’à les appliquer :
–
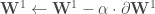
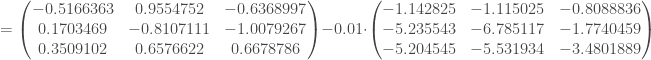
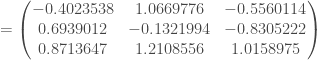
–
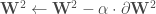

–
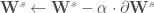

Les trois jeux de pondérations étant désormais mis à jour, on peut lancer la seconde itération. Sans reprendre les calculs, car il s’agit exactement des mêmes et seul 


Au bout de 


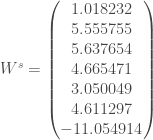
Les performances obtenues peuvent être décrites au travers de la matrice de confusion suivante :
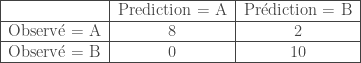
, soit un taux de bonne classification globale de 

Les bandes rouges correspondent à la région de la classe « A » construite par le modèle, en bleu celle de la classe « B ». En rouge les données réelles de la classe « A » et en vert celles de la classe « B »
Soit l’exemple suivant :
BDD = data.frame(Y = c(rep(0,10),rep(1,10)),
X1 = c(8.1472, 9.0579, 1.2699, 9.1338, 6.3236, 0.9754, 2.7850, 5.4688, 9.5751, 9.6489, 1.5761, 9.7059, 9.5717, 4.8538, 8.0028, 1.4189, 4.2176, 9.1574, 7.9221, 9.5949),
X2 = c(3.1101, 4.1008, 4.7876, 7.0677, 6.0858, 4.9309, 4.0449, 3.0101, 5.9496, 6.8729, 1.0898, 1.9868, 2.9853, 10.0080, 8.9052, 8.0411, 2.0826, 1.0536, 9.0649, 10.0826))
Package et fonction R: neuralnet: Training of Neural Networks (r-project.org)
La fonction neuralnet du package du même nom permet de réaliser des réseaux de neurones. Après chargement du package, on lance sa conception de la manière suivante :
neuralnet(Y ~ x1 + x2, data = BDD, hidden = c(3,6), algorithm = « backprop », learningrate = 0.1, act.fct = « logistic », linear.output = FALSE, lifesign = « full », constant = TRUE)
Parmi les éléments à insérer les plus importants il faut relever :
– La formule définissant variable réponse (à gauche) et variables explicatives (à droite) : 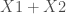
– La base de données sur laquelle on souhaite travailler : 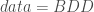
– Le nombre de couches cachées et de neurones par couche : 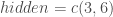
– L’utilisation de l’algorithme de rétropropagation : 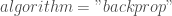
– Le taux d’apprentissage nécessaire pour définir la vitesse à laquelle on rectifie les pondérations : 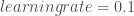
– La fonction d’activation, ici la fonction sigmoïde : 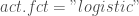
– L’affichage de tous les résultats obtenus : 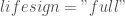
– Le choix d’un modèle non linéraire : 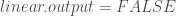
On obtient alors les résultats suivants :
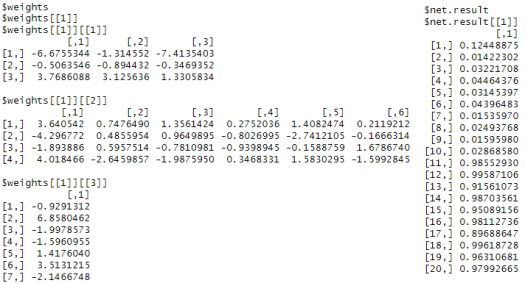
, avec, à gauche, les poids finaux par couche et, à droite, les scores de prédiction.
Les différences obtenues avec les calculs manuels (cf partie « Exemple ») sont explicables du fait que la fonction neuralnet est bien plus complète et permet de lancer des réseaux de neurones bien plus élaborés que celui présenté dans cet article.
Soit l’exemple suivant :
data BDD;
input x1 x2 Y;
cards;
8.1472 3.1101 0
9.0579 4.1008 0
1.2699 4.7876 0
9.1338 7.0677 0
6.3236 6.0858 0
0.9754 4.9309 0
2.7850 4.0449 0
5.4688 3.0101 0
9.5751 5.9495 0
9.6489 6.8729 0
1.5761 1.0898 1
9.7059 1.9868 1
9.5717 2.9853 1
4.8538 10.0080 1
8.0028 8.9052 1
1.4189 8.0411 1
4.2176 2.0826 1
9.1574 1.0536 1
7.9221 9.0649 1
9.5949 10.0826 1
;
run;
Le logiciel SAS offre un module complet pour la production de réseaux de neurones : SAS Visual Data Mining and Machine Learning. Cependant, ce dernier n’est pas disponible dans le package de base, tout comme le module IML pour les calculs matriciels. Par conséquent, on proposera la macro suivante :
, qu’il faudra coupler à la macro suivante permettant de calculer les produits scalaires nécessaires :
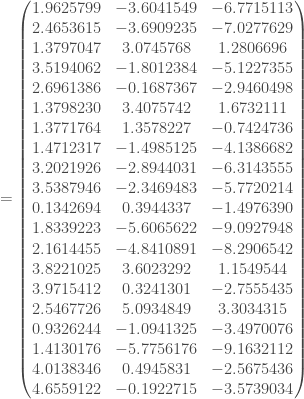
On lance le réseau de neurones dans un objectif de déterminer le modèle prédictif. On doit alors produire dans un premier temps les différents poids 
data w1;
input w1_1 w1_2 w1_3;
cards;
-0.5166363 0.9554752 -0.6368997
0.1703469 -0.8107111 -1.0079267
0.3509102 0.6576622 0.6678786
;
run;
data w2;
input w2_1 w2_2 w2_3 w2_4 w2_5 w2_6;
cards;
1.076244 1.2653173 1.6323954 0.26325727 0.1376167 1.0766192
-1.586651 0.3370436 0.5188823 0.65283448 -0.9157413 -0.6095473
-1.382789 0.7540253 -0.8235877 0.01111528 0.3684991 1.4985495
0.712537 -1.8088945 -1.2941944 -0.44789165 -0.1230735 -0.3934913
;
run;
data w3;
input w;
cards;
-0.1755870
1.2174536
0.8050443
0.4084043
1.3316199
1.2032622
-0.3737364
;
run;
On applique la macro de la manière suivante :
%neuralNetwork(DATA = BDD, REPONSE = Y, W = W1 W2 W3, LEARN_RATE = 0.1, ITERATION = 50, TYPE = M);
Parmi les éléments à insérer, il faut relever :
– Le tableau sur lequel on veut travailler : 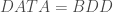
– Le nom de la réponse à discriminer : 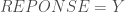
– La liste des matrices des poids : 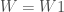
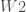
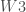
– Le taux d’apprentissage, qui servira à définir à quel vitesse l’on applique les matrices correctrices des poids : 
– Le nombre d’itérations à réaliser : 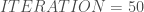
– Le mode d’utilisation de la macro : 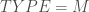
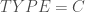
On obtient alors les résultats suivants parmi les tableaux générés en fin de procédure :
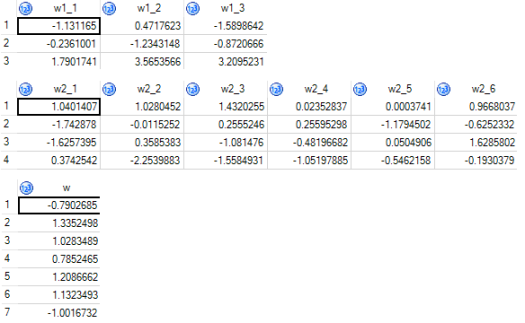
, puis :

, et :

La première série de tableaux présente les pondérations finales :
L’algorithme implémenté tel quel est particulièrement long en calcul, aussi il n’a été testé que pour 
– Probabilité, analyse des données et statistiques de Gilbert Saporta ;
– The Elements of Statsticial Learning de Trevor Hastie, Robert Tibshirani et Jerome Friedman ;
– Data mining et statistique décisionnelle, l’intelligence des données de Stéphane Tufféry ;
– Comprendre le deep learning, une introduction aux réseaux de neurones de Jean-Claude Heudin ;
– Le site web : https://datafuture.fr/post/fabrique-ton-premier-reseau-de-neurones/
