



- Présentation
- Les différentes versions du test
- Cas pour échantillons non appariés
- Si
et calcul de la p-valeur exacte
- L’approximation de Wilcoxon dans le cas d’ex-aequo
- Le
de Mann-Whitney
- Conditions pour le rejet de
- Si
- Cas pour échantillons appariés
- Si
et calcul de la p-valeur exacte
- Le test du signe
- Conditions pour le rejet de
- Si
- Cas pour échantillons non appariés
- Calcul de la p-valeur dans le cadre de la loi normale centrée-réduite
- Table de la loi normale centrée-réduite
- Algorithme de calcul
- Tendance lorsque
- Annexe théorique
- Calcul de
dans le cadre de la version non appariée du test de Wilcoxon
- Similitude entre la statistique
et le
- Calcul de
dans le cadre de la version appariée du test de Wilcoxon
- Calcul de
- Exemple
- Cas pour échantillons non appariés : les tests de la somme des rangs de Wilcoxon et le
- Cas pour échantillons appariés
- Le test des rangs signés de Wilcoxon
- Le test du signe
- Cas pour échantillons non appariés : les tests de la somme des rangs de Wilcoxon et le
- Application sous R
- Cas pour échantillons non appariés : les tests de la somme des rangs de Wilcoxon et du
- Cas pour échantillons appariés
- Le test des rangs signés de Wilcoxon
- Le test du signe
- Cas pour échantillons non appariés : les tests de la somme des rangs de Wilcoxon et du
- Application sous SAS
- Cas pour échantillons non appariés : les tests de la somme des rangs de Wilcoxon et du
- Cas pour échantillons appariés
- Le test des rangs signés de Wilcoxon
- Le test du signe
- Cas pour échantillons non appariés : les tests de la somme des rangs de Wilcoxon et du
- Bibliographie
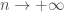
Publié en 1945 par Frank Wilcoxon, le test de Wilcoxon est une approche non paramétrique permettant de :
– Tester la liaison entre une variable continue ou ordinale 
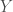
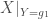

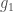
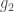
– Tester la liaison entre deux variables continues ou ordinales appariées 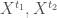
Que les données soient appariées ou non, le test de Wilcoxon est souvent vu comme l’alternative au test de Student lorsqu’elles ne respectent les hypothèses de normalité requises.
Enfin, cet article présentera également le
Cas pour échantillons non appariés
Hypothèse préliminaire:
Soit 
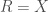




On définit l’espérance de la statistique de test : 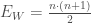

La statistique de test de la somme des rangs de Wilcoxon est :

Si 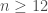

, qui suit une loi normale centrée-réduite. L’hypothèse 
Les deux groupes sont semblables /

Soit 

– 

– 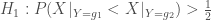

– 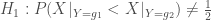

Si
Dans le cas où
La p-valeur se détermine selon l’algorithme suivant :
– Étape 1 : déterminer la matrice des combinaisons de rangs possibles de taille 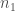
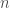
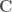
– Étape 2 : calculer la somme de chaque combinaison de rang et déterminer la valeur minimale 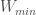
– Étape 3 : ne retenir que les cas compris dans ![[W_{min}, W]](https://s0.wp.com/latex.php?latex=%5BW_%7Bmin%7D%2C+W%5D&bg=ffffff&fg=404040&s=0&c=20201002)

– Etape 4 : avant toute chose il faut ici se souvenir du groupe de référence car cela va impacter le type de test voulu (unilatéral à droite, à gauche et bilatéral). Il faudrait alors appliquer les étapes 1 à 3 avec la référence initiale dont on notera les fréquences 



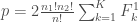
A noter que dans le cas où les p-valeurs associées au test unilatéral à gauche ou à droite sont les mêmes (ce qui peut arriver selon la distribution considérée), elles sont également supérieures à 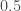
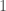
L’Approximation de Wilcoxon dans le cas d’ex-aequo :
Si on compte un nombre trop important d’ex-aequos au sein des rangs de 
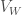

Avec 

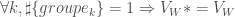
Le
Publié en 1947 suite aux travaux de Henry Berthold Mann et Donald Ransom Whitney, le test de Mann-Whitney, également appelé U-test, est un test donnant des résultats strictement équivalent au test de Wilcoxon. En effet, une relation linéaire peut-être mise en évidence entre les deux statistiques de test. Néanmoins, le test de Wilcoxon reste relativement le plus populaire et le plus utilisé par les praticiens.
La formule de la statistique de test
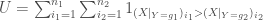
Si

La p-valeur se détermine selon l’algorithme décrit pour le test de la somme des rangs de Wilcoxon. Il faudra au préalable transformer

Dans le cas où 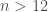

Avec,
– 
– 
Et comparer la statistique de test
Conditions pour le rejet de
Plus la statistique de test 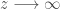
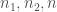
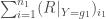

Ainsi, une localisation des 
Cas pour échantillons appariés
Hypothèse préliminaire:
Soit 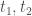
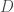
![\forall i \in [1, \cdots, n]](https://s0.wp.com/latex.php?latex=%5Cforall+i+%5Cin+%5B1%2C+%5Ccdots%2C+n%5D&bg=ffffff&fg=404040&s=0&c=20201002)

Et 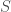

La seconde étape consiste à éliminer de 
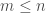
Dés lors deux formes différentes vont être utilisées afin de calculer la statistique des rangs signés de Wilcoxon, le cas sans ex-aequos:
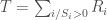
, et le cas avec ex-aequos:

On considère 

, d’espérance 

Pour 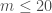

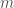
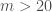
Enfin, l’hypothèse
Aucune différence de population /

Soit
– 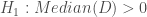
– 
– 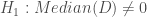
Si
Dans le cas où

N’ayant pas eu le bonheur de mettre la main sur la fonction de répartition de cette loi, on se basera sur l’algorithme un peu « bourrin » ci-dessous pour en déterminer la p-valeur.
Soit

, les 

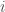
L’idée est alors de déterminer pour toutes les valeurs comprises entre 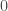
Étape 1 : Générer toutes les combinaisons possibles de
- Pour chaque valeur entière de l’intervalle
que l’on notera
, déterminer les
combinaisons dont la somme
;
- Étant donné que le paramètre
, chaque combinaison donnant la somme
, puisque issue de
avec
le nombre de
nécessaires et
celui où
. Dès lors, la probabilité de tirer

Étape 2 : On sommera les probabilités associées aux valeurs entières de l’intervalle ![[0,T]](https://s0.wp.com/latex.php?latex=%5B0%2CT%5D&bg=ffffff&fg=404040&s=0&c=20201002)

A noter le cas où 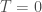
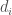


Enfin, la p-valeur obtenue correspond à l’approche unilatéral à gauche ou à droite en fonction du sens des différences retenues. Afin de passer sur une version bilatérale, on prendra la p-valeur associé à celle unilatérale à gauche et on la multipliera par deux.
Le test du signe :
Le test du signe est un concurrent au test des rangs signés de Wilcoxon. Néanmoins, ce dernier demeure plus puissant et donc plus souvent utilisé car tenant compte de la variance contrairement au test du signe. Il a été publié en 1710 par John Arbuthnott puis étendu par Nicholas Bernouilli en 1713.
On considère l’ensemble des paires appariées 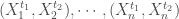

Elle suit une loi binomiale de paramètres 
Si

, à la table de la loi normale centrée-réduite. Avec l’espérance : 

Dans ce cas là, on s’appuiera sur la table de la loi binomiale suivante (pour 

Le calcul de la p-valeur se fait via la formule qui suit. En notant ![E[.]](https://s0.wp.com/latex.php?latex=E%5B.%5D&bg=ffffff&fg=404040&s=0&c=20201002)
– Pour un test unilatérale à gauche (on utilisera la statistique 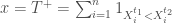

![p = P(X \leq x) = \frac{1}{2 ^n} \sum_{k = 1} ^{E[X]} \frac{n !}{(n - k)! k !}](https://s0.wp.com/latex.php?latex=p+%3D+P%28X+%5Cleq+x%29+%3D+%5Cfrac%7B1%7D%7B2+%5En%7D+%5Csum_%7Bk+%3D+1%7D+%5E%7BE%5BX%5D%7D+%5Cfrac%7Bn+%21%7D%7B%28n+-+k%29%21+k+%21%7D&bg=ffffff&fg=404040&s=0&c=20201002)
– Pour un test bilatérale (on utilisera la statistique
![p = 2 \frac{1}{2 ^n} \sum_{k = 1} ^{E[X]} \frac{n !}{(n - k)! k !}](https://s0.wp.com/latex.php?latex=p+%3D+2+%5Cfrac%7B1%7D%7B2+%5En%7D+%5Csum_%7Bk+%3D+1%7D+%5E%7BE%5BX%5D%7D+%5Cfrac%7Bn+%21%7D%7B%28n+-+k%29%21+k+%21%7D&bg=ffffff&fg=404040&s=0&c=20201002)
Conditions pour le rejet de
Plus 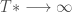

Pour cas 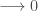





Les deux versions du test de Wilcoxon, le
La table de la loi normale centrée-réduite :

Algorithme de calcul :
Étant donné que la fonction de répartition de la loi centrée-réduite est basée sur la fonction erreur 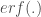
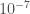

La formule d’usage et faisant intervenir aussi bien 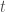
– Dans le cadre unilatéral à gauche,

– Dans le cadre unilatéral à droite,

– Dans le cadre bilatéral,
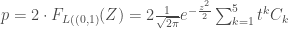
Avec,
– 
– 
– 
– 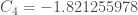
– 

Le test de Wilcoxon se base sur la loi normale centrée-réduite qui est indépendante de
On proposera de simuler plusieurs échantillons selon cinq tailles différentes: 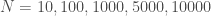
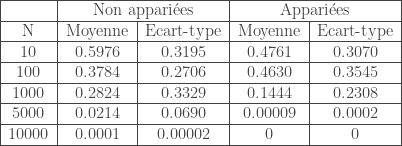
De manière hâtive, on reste en adéquation avec l’hypothèse de construction de la statistique de test 
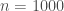




Cette simulation montre que le test de Wilcoxon est atteint par la malédiction des grands échantillons.
– Calcul de
La statistique 
– ![E_W = E[W] = E(\sum_{i = 1} ^n i \cdot Z_i) = E[Z_i] \cdot \sum_{i = 1} ^n i = \frac{n_1}{n} \times \frac{n \cdot (n + 1)}{2} = \frac{n_1 \cdot (n + 1)}{2}](https://s0.wp.com/latex.php?latex=E_W+%3D+E%5BW%5D+%3D+E%28%5Csum_%7Bi+%3D+1%7D+%5En+i+%5Ccdot+Z_i%29+%3D+E%5BZ_i%5D+%5Ccdot+%5Csum_%7Bi+%3D+1%7D+%5En+i+%3D+%5Cfrac%7Bn_1%7D%7Bn%7D+%5Ctimes+%5Cfrac%7Bn+%5Ccdot+%28n+%2B+1%29%7D%7B2%7D+%3D+%5Cfrac%7Bn_1+%5Ccdot+%28n+%2B+1%29%7D%7B2%7D&bg=ffffff&fg=404040&s=0&c=20201002)
–
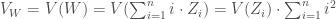


– Similitude entre la statistique
La statistique de Mann-Whitney est de la forme :
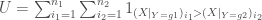
, et plus particulièrement:
–

–
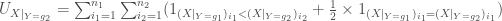
Il faut voir le calcul de la somme des rangs de manière inverse, c’est-à-dire :
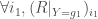
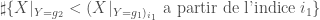
, on remarque que l’on applique un décalage de l’indice 


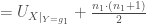

Or 

La statistique ![E[Z_i] = \frac{1}{2}](https://s0.wp.com/latex.php?latex=E%5BZ_i%5D+%3D+%5Cfrac%7B1%7D%7B2%7D&bg=ffffff&fg=404040&s=0&c=20201002)
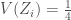
–
![E(T / R) = \sum_{i = 1} ^n R_i \cdot E[Z_i] = E[Z_i] \cdot \sum_{i = 1} ^n R_i = \frac{1}{2} \times \frac{n \cdot (n + 1)}{2} = \frac{n \cdot (n + 1)}{4}](https://s0.wp.com/latex.php?latex=E%28T+%2F+R%29+%3D+%5Csum_%7Bi+%3D+1%7D+%5En+R_i+%5Ccdot+E%5BZ_i%5D+%3D+E%5BZ_i%5D+%5Ccdot+%5Csum_%7Bi+%3D+1%7D+%5En+R_i+%3D+%5Cfrac%7B1%7D%7B2%7D+%5Ctimes+%5Cfrac%7Bn+%5Ccdot+%28n+%2B+1%29%7D%7B2%7D+%3D+%5Cfrac%7Bn+%5Ccdot+%28n+%2B+1%29%7D%7B4%7D&bg=ffffff&fg=404040&s=0&c=20201002)
–
![V(T / R) = \sum_{i = 1} ^n R_i ^2 \cdot V[Z_i] = V[Z_i] \cdot \sum_{i = 1} ^n R_i ^2](https://s0.wp.com/latex.php?latex=V%28T+%2F+R%29+%3D+%5Csum_%7Bi+%3D+1%7D+%5En+R_i+%5E2+%5Ccdot+V%5BZ_i%5D+%3D+V%5BZ_i%5D+%5Ccdot+%5Csum_%7Bi+%3D+1%7D+%5En+R_i+%5E2&bg=ffffff&fg=404040&s=0&c=20201002)

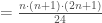
Cas pour échantillons non appariés : Les tests de la somme des rangs de Wilcoxon et du
Soit la variable aléatoire 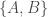

Ci-dessous, les boxplots des distributions de

Afin de calculer la statistique de test de Wilcoxon, on va d’abords ordonner le vecteur

On a pour 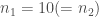

A noter que 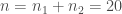
Avant de continuer, on peut également calculer le

, grâce auquel on détermine maintenant le nombre de fois où chaque valeur de 


On poursuit avec le calcul de la p-valeur associée à la statistique de Wilcoxon. On se reportera à la table de la loi de Mann-Whitney pour la statistique de test équivalente à celle de Wilcoxon (

Concernant le calcul de la p-valeur exacte, on détermine la matrice des combinaisons de 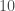



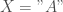

![W \in [55, 105]](https://s0.wp.com/latex.php?latex=W+%5Cin+%5B55%2C+105%5D&bg=ffffff&fg=404040&s=0&c=20201002)
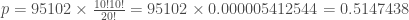
On est en présence d’une p-valeur en unilatérale supérieure à 
Dans le cas où l’on veut se reporter à la loi normale centrée-réduite :
– L’espérance 
– La variance 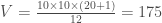
La statistique de test vaut alors :

On cherche à tester bilatéralement le rejet de l’hypothèse 


En se reportant aux valeurs de la table de la loi normale centrée-réduite ci-dessus, on constate que,

Maintenant, on calcul la p-valeur associée à la statistique de test 

On peut calculer maintenant la p-valeur,


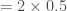

On ne pourra pas rejeter 
Cas pour échantillons appariés
Soit l’échantillon apparié 

Ci-dessous le nuage de points basé sur ces données,

La représentation graphique montre, outre la différence de valeurs aux deux temps, une absence de linéarité entre 
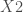
Le test des rangs signés de Wilcoxon :
On veut appliquer le test de Wilcoxon sur les données appariées

Aucun ex-aequo et aucune valeur 


Dans un premier temps on se reportera à la table de la loi signée de Wilcoxon dans le cadre bilatéral,
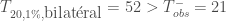
Concernant le calcul de la p-valeur exacte, on détermine la matrice des combinaisons de 

On obtient alors la p-valeur suivante dans un cadre bilatéral :

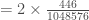
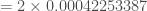

Dans le cas où on souhaite se baser sur la loi normale centrée-réduite, on doit déterminer :
– L’Espérance, 
– Et la variance, 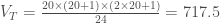
La statistique de test vaut alors:

On cherche à tester bilatéralement le rejet de l’hypothèse

En se reportant aux valeurs de la table de la loi normale centrée-réduite ci-dessus, on constate que,
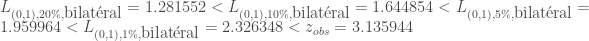
Maintenant, on calcul la p-valeur associée à la statistique de test

On peut calculer maintenant la p-valeur,

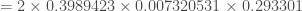

On pourra rejeter 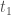

Le test du signe :
On applique maintenant le test du signe au couple 



Dans un premier temps on se reportera à la table de la loi binomial,
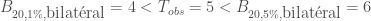
Concernant le calcul de la p-valeur exacte dans le cadre bilatéral,
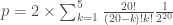
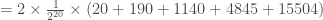



Dans le cas où on souhaite se baser sur la loi normale centrée-réduite, on calcul l’espérance 
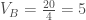

On cherche à tester bilatéralement le rejet de l’hypothèse

En se reportant aux valeurs de la table de la loi normale centrée-réduite ci-dessus, on constate que,

Maintenant, on calcul la p-valeur exacte associée à la statistique de test

On peut calculer maintenant la p-valeur,

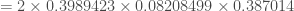

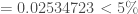
On pourra rejeter
Cas pour échantillons non appariés : Les tests de la somme des rangs de Wilcoxon et du
Dans un premier temps, on charge notre exemple:
X_Y1 = c(3.1101,4.1008,4.7876,7.0677,
6.0858,4.9309,4.0449,3.0101,5.9495,6.8729)
X_Y2 = c(1.0898,1.9868,2.9853,10.0080,8.9052,
8.0411,2.0826,1.0536,9.0649,10.0826)
Package et fonction R: http://stat.ethz.ch/R-manual/R-patched/library/stats/html/wilcox.test.html
La fonction wilcox.test du package stats permet d’appliquer les différentes versions du test de Wilcoxon sur données non appariés ou appariés. Le package se charge automatiquement lors du lancement de R.
On lance le test de Wilcoxon afin de savoir si les rangs de 
wilcox.test(X_Y1,X_Y2,paired=FALSE)
Parmi les éléments à insérer les plus importants il faut relever :
– Les deux échantillons sur lesquels appliquer le test : X_Y1, X_Y2 ;
– Si les données sont non appariées : paired = FALSE ;
– On aurait pu rajouter l’instruction « alternative » qui permettra de déterminer si on veut procéder à un test bilatéral, unilatéral à gauche ou à droite. Par défaut le logiciel R lance le test dans un cadre bilatéral ;
– On aurait pu rajouter l’instruction « exact » qui permettra de déterminer si l’on veut se baser sur la loi de distribution de la loi centrée-réduite (TRUE) ou celle de Wilcoxon (FALSE, soit l’option par défaut).
On obtient alors les résultats suivants:

On vérifie :
– Les données utilisées: « data: X_Y1 and X_Y2 » ;
– La statistique de test: « 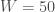
– La p-valeur: « 
– Et le type de test effectué: « alternative hypothesis: true location shift is not equal to
Concernant le test du
Cas pour échantillons appariés
Dans un premier temps, on charge notre exemple:
X_t1 = c(3.1101,4.1008,4.7876,7.0677,6.0858,4.9309,
4.0449,3.0101,5.9496,6.8729,1.0898,1.9868,2.9853,10.0080,
8.9052,8.0411,2.0826,1.0536,9.0649,10.0826)
X_t2 = c(0.8970,2.0949,3.0307,4.0135,5.0515,6.0261,
6.9059,7.9838,8.9854,9.9468,11.1682,11.9124,12.9516,
13.9288,14.8826,15.9808,16.9726,18.1530,18.9751,19.8936)
Le test des rangs signés de Wilcoxon :
Package et fonction R: http://stat.ethz.ch/R-manual/R-patched/library/stats/html/wilcox.test.html
La fonction wilcox.test du package stats permet d’appliquer les différentes versions du test de Wilcoxon sur données appairées ou non appariées. Le package se charge automatiquement lors du lancement de R.
On lance le test de Wilcoxon afin de savoir si
wilcox.test(X_t1,X_t2,paired=TRUE)
Parmi les éléments à insérer les plus importants il faut relever:
– Les deux échantillons sur lesquels appliquer le test : X_t1, X_t2 ;
– Si les données sont appariées : paired = TRUE;
– On aurait pu rajouter l’instruction « alternative » qui permettra de déterminer si on veut procéder à un test bilatéral, unilatéral à gauche ou à droite. Par défaut le logiciel R lance le test dans un cadre bilatéral.
– On aurait pu rajouter l’instruction « exact » qui permettra de déterminer si l’on veut se baser sur la loi de distribution de la loi centrée-réduite (TRUE) ou celle de Wilcoxon (FALSE, soit l’option par défaut).
On obtient alors les résultats suivants :

On vérifie :
– Les données utilisées: « data: X_t1 and X_t2 » ;
– La statistique de test: « 
– La p-valeur: « 
– Et le type de test effectué: « alternative hypothesis: true location shift is not equal to
Le test du signe :
Package et fonction R: https://www.rdocumentation.org/packages/BSDA/versions/1.2.0/topics/SIGN.test
La fonction SIGN.test du package BSDA permet d’appliquer le test du signe.
On lance le test du signe afin de savoir si
SIGN.test(X_t1,X_t2)
Parmi les éléments à insérer les plus importants il faut relever:
– Les deux échantillons sur lesquels tester l’égalité des médianes : X_t1, X_t2 ;
– On aurait pu rajouter l’instruction « alternative » qui permettra de déterminer si on veut procéder à un test bilatéral, unilatéral à gauche ou à droite. Par défaut le logiciel R lance le test dans un cadre bilatéral.
On obtient alors les résultats suivants :

On vérifie :
– Les données utilisées: « data: X_t1 and X_t2 » ;
– La statistique de test: « 
– La p-valeur: « 
– Et le type de test effectué: « alternative hypothesis: true median difference is not equal to
Cas pour échantillons non appariés : Les tests de la somme des rangs de Wilcoxon et du
Soit l’exemple suivant:
data E;
input Y $1. X;
cards;
A 3.1101
A 4.1008
A 4.7876
A 7.0677
A 6.0858
A 4.9309
A 4.0449
A 3.0101
A 5.9495
A 6.8729
B 1.0898
B 1.9868
B 2.9853
B 10.0080
B 8.9052
B 8.0411
B 2.0826
B 1.0536
B 9.0649
B 10.0826
;
run;
Procédure SAS : http://support.sas.com/documentation/cdl/en/statug/63033/HTML/default/viewer.htm#statug_npar1way_sect022.htm
On lance le test de Wilcoxon pour données non appariées afin de savoir si 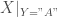

proc npar1way wilcoxon data = E;
class Y;
var X;
ods exclude WilcoxonScores KruskalWallisTest;
run;
Parmi les éléments à insérer les plus importants il faut relever :
– La table contenant nos données: data = E ;
– L’utilisation du test de Wilcoxon: proc npar1way wilcoxon ;
– La variable sur laquelle appliquer le test : var
– La variable binaire permettant de scinder
– L’ods output est utilisé afin de filtrer les résultats et n’afficher que ceux dont on a besoin.
On obtient alors les résultats suivants:

On vérifie :
– Sur la ligne « Statistique » , la statistique de test: « 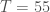
– Sur la ligne « Bilatéral » du paragraphe « Approximation normale », la p-valeur : «
Concernant le test du
Cas pour échantillons appariés
Soit l’exemple suivant:
data E;
input X_t1 X_t2;
cards;
3.1101 0.8970
4.1008 2.0949
4.7876 3.0307
7.0677 4.0135
6.0858 5.0515
4.9309 6.0261
4.0449 6.9059
3.0101 7.9838
5.9496 8.9854
6.8729 9.9468
1.0898 11.1682
1.9868 11.9124
2.9853 12.9516
10.0080 13.9288
8.9052 14.8826
8.0411 15.9808
2.0826 16.9726
1.0536 18.1530
9.0649 18.9751
10.0826 19.8936
;
run;
Le test des rangs signés de Wilcoxon :
Procédure SAS : http://support.sas.com/documentation/cdl/en/procstat/66703/HTML/default/viewer.htm#procstat_univariate_details84.htm
On lance le test des rangs signés de Wilcoxon afin de savoir si les rangs des valeurs de
data E;
set E;
diff = X_t1 – X_t2;
run;
proc univariate data = E;
var diff;
ods exclude Moments BasicMeasures Quantiles ExtremeObs;
run;
Parmi les éléments à insérer les plus importants il faut relever:
– La table contenant nos données: data = E ;
– La variable sur laquelle porte le test: var diff , qui correspond à la différence entre
– L’ods output est utilisé afin de filtrer les résultats et n’afficher que ceux dont on a besoin.
On obtient alors les résultats suivants:

On vérifie:
– Dans la colonne « Statistique » à la ligne « Signed Rank », la statistique de test 
– Dans la colonne « P-value » à la ligne « Signed Rank » , la p-valeur : « 
Le test du signe :
Procédure SAS : http://support.sas.com/documentation/cdl/en/procstat/66703/HTML/default/viewer.htm#procstat_univariate_details84.htm
On lance le test du signe afin de savoir si les rangs des valeurs de
data E;
set E;
diff = X_t1 – X_t2;
run;
proc univariate data = E;
var diff;
ods exclude Moments BasicMeasures Quantiles ExtremeObs;
run;
Parmi les éléments à insérer les plus importants il faut relever:
– La table contenant nos données: data = E ;
– La variable sur laquelle porte le test: var diff , qui correspond à la différence entre
– L’ods output est utilisé afin de filtrer les résultats et n’afficher que ceux dont on a besoin.
On obtient alors les résultats suivants:
On vérifie:
– Dans la colonne « Statistique » à la ligne « Signe », la statistique de test 

– Dans la colonne « P-value » à la ligne « Sign » , la p-valeur : « 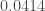
– Individual comparisons by ranking methods de Franck Wilcoxon
– Statistique, dictionnaire encyclopédique de Yadolah Dodge
– Probabilité, analyse de données et statistique de Gilbert Saporta
– Le document : https://jonathanlenoir.files.wordpress.com/2013/12/tables-mann-whitney-wilcoxon-kruskal-wallis.pdf
– Méthodes et modèles en statistique non paramétrique, exposé fondamental de Philippe capéraà et Bernard Van Cutsem
