



- Présentation
- Le test
- La table de la loi centrée-réduite
- Calcul de la p-valeur exacte si
- Calcul de la p-valeur exacte si
- Tendance pour le rejet de
- Tendance lorsque
- Annexe théorique
- Exemple
- Application sous R
- Application sous SAS
- Bibliographie
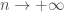
Le test binomial, également appelé test exact binomial, a été publié par Ronald Aylmer Fisher en 1925. Il s’agit d’une approche non paramétrique permettant de tester si la répartition des deux groupes d’une variable binaire 
A l’instar du test exact de Fisher, le test binomial est connu comme une alternative au test du 
Hypothèse préliminaire :
La statistique de test binomial est,

Où 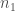
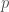
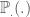
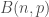
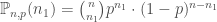
Deux cas de figure sont à prendre en compte pour le calcul de la p-valeur associée à 

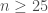
![z = |\frac{b - \mathbb{E}[b]}{\sigma_b}|](https://s0.wp.com/latex.php?latex=z+%3D+%7C%5Cfrac%7Bb+-+%5Cmathbb%7BE%7D%5Bb%5D%7D%7B%5Csigma_b%7D%7C&bg=ffffff&fg=404040&s=0&c=20201002)
, où ![\mathbb{E}[b] = n \cdot p](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bb%5D+%3D+n+%5Ccdot+p&bg=ffffff&fg=404040&s=0&c=20201002)

Que l’on fasse usage de la statistique de test 
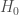
Il n’y a pas de différence entre les fréquences observées et attendues /

En restant sur le cas le plus fréquent et en lien avec des échantillons en général de grande taille, on pose 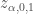
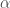
– 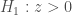
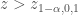
– 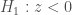
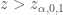
– 

La table de la loi normale centrée-réduite

Calcul de la p-valeur exacte si
– Calculer 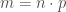
– Si 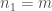
– Sinon, on pose 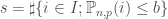
- Si
alors calculer
sur
et la p-valeur de forme :
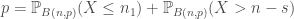
- Si
alors calculer
et la p-valeur de forme :

On a défini là la version bilatéral du test. Pour passer sur une version unilatéral à droite il faut se contenter d’utiliser le terme de gauche, tandis que pour celle forme à gauche ce sera celui de droite.
Calcul de la p-valeur exacte si
La loi à laquelle reporter la statistique de test 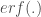
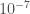

La formule d’usage et faisant intervenir aussi bien 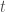
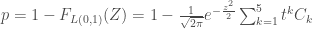
Avec,
– 
– 
– 
– 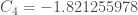
– 
Tendance pour le rejet de
En fonction de la taille d’échantillon, deux approches sont à considérer. Pour la plus simple (
Pour celle un peu plus complexe (
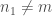
–

–
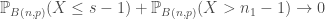
Puisqu’une probabilité ne peut pas être négative, finalement la méthode consiste à comparer directement la probabilité ce qui se passe sur les queues de la distribution. Plus elles sont lourdes et moins on a de chances de rejeter

On s’intéresse désormais à la résistance du test binomial au fur et à mesure que la taille d’échantillon croît. Etant donné que la statistique de test suit une loi normale centrée-réduite, elle-même indépendante de 
![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=404040&s=0&c=20201002)
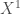

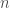
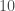


De manière hâtive, on reste en adéquation avec l’hypothèse de construction de la statistique de test binomial jusqu’à 



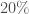
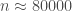

Cette simulation montre que le test binomial est assez robuste à la malédiction des grands échantillons.
On présente ici la démonstration du calcul de l’espérance et de la variance de la loi Binomiale.
Dans un premier temps, il faut savoir que si 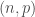

![\mathbb{E}[X_i] = p](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_i%5D+%3D+p&bg=ffffff&fg=404040&s=0&c=20201002)
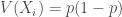
Dès lors, on a,
![\mathbb{E}[X] = \mathbb{E}[\sum_{i = 1} ^n X_i] = \sum_{i = 1} ^n \mathbb{E}[X_i] = \sum_{i = 1} ^n p = n \cdot p](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX%5D+%3D+%5Cmathbb%7BE%7D%5B%5Csum_%7Bi+%3D+1%7D+%5En+X_i%5D+%3D+%5Csum_%7Bi+%3D+1%7D+%5En+%5Cmathbb%7BE%7D%5BX_i%5D+%3D+%5Csum_%7Bi+%3D+1%7D+%5En+p+%3D+n+%5Ccdot+p&bg=ffffff&fg=404040&s=0&c=20201002)
Et,

Soit l’échantillon suivant,

Afin d’illustrer cet exemple, on réalise un diagramme en camembert :

On a 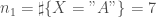

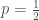
Donc,
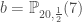
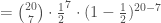
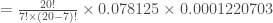
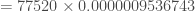

Maintenant que l’on a la statistique de test, on souhaite déterminer la p-valeur. Comme 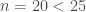
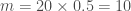
Or ![[10,20]](https://s0.wp.com/latex.php?latex=%5B10%2C20%5D&bg=ffffff&fg=404040&s=0&c=20201002)
![\forall i \in[10,20]](https://s0.wp.com/latex.php?latex=%5Cforall+i+%5Cin%5B10%2C20%5D&bg=ffffff&fg=404040&s=0&c=20201002)


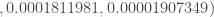
D’où,
![s = \sharp \lbrace i \in [10;20]; \mathbb{P}_{20,\frac{1}{2}} (i) \leq 0.07392883 \rbrace = 7](https://s0.wp.com/latex.php?latex=s+%3D+%5Csharp+%5Clbrace+i+%5Cin+%5B10%3B20%5D%3B+%5Cmathbb%7BP%7D_%7B20%2C%5Cfrac%7B1%7D%7B2%7D%7D+%28i%29+%5Cleq+0.07392883+%5Crbrace+%3D+7&bg=ffffff&fg=404040&s=0&c=20201002)
Enfin,





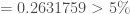
On en conclut que l’on ne peut pas rejeter
Soit l’exemple suivant :
X = c(« A », »A », »A », »B », »B », »B », »B », »A », »A », »A », »A », »B », »B », »B », »B », »B », »B », »B », »B », »B »)
Package et fonction R : https://stat.ethz.ch/R-manual/R-devel/library/stats/html/binom.test.html
La fonction binom.test du package stats permet de lancer le test binomial afin de comparer la répartition des modalités de 
binom.test(x = table(X), p = 0.5, alternative = « two.sided »)
Parmi les éléments à insérer les plus importants il faut relever :
– La variable que l’on souhaite étudier : 
– La proportion de référence : 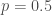
– La version bilatérale du test : 
On obtient les résultats suivants :

On vérifie :
– La proportion observée : « number of successes 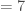
– La taille de l’échantillon : « number of trials 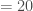
– La p-valeur : « 
Soit l’exemple suivant :
data E;
input X $1.;
cards;
A
A
A
B
B
B
B
A
A
A
A
B
B
B
B
B
B
B
B
B
;
run;
Procédure SAS: http://support.sas.com/documentation/cdl/en/procstat/63104/HTML/default/procstat_freq_sect028.htm
La procédure FREQ permet de lancer le test binomial afin de comparer la répartition des modalités de
proc freq data = E;
tables X / binomial (equiv p = 0.5);
run;
Parmi les éléments à insérer les plus importants il faut relever :
– La variable que l’on souhaite croiser : tables X ;
– L’utilisation du test binomial : 
– La proportion de référence : 
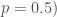
On obtient les résultats suivants :
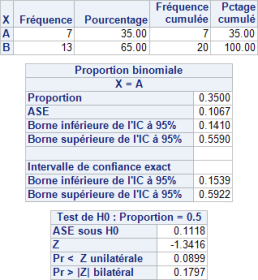
On vérifie :
– Le premier tableau qui donne les effectifs par modalité de
– Dans le second tableau, on retrouve des éléments descriptifs dont la proportion observée ainsi que les intervalles de confiance ;
– Dans le troisième tableau, on retrouve la p-valeur 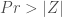

– Statistique. Dictionnaire encyclopédique de Yadolah Dodge ;
– The use of confidence or fiducial limits illustrated in the case of the binomial de C. J. Clopper et E. S. Pearson ;
– Goodness-of-fit statistics for discrete multivariate data de T. R. C. Read et N. A. C. Cressie.
